

検索モデルと生成モデル
服が我々にとって必需品であると同様、検索も我々にとって欠かせないサービスである。今、生成AIも同じ道を歩みつつある。では、服を買う時にプレタポルテとオートクチュールのどちらを選ぶだろう?ここではお財布と相談なしに。唐突な問いだが、両者の関係は検索モデルと生成モデルの関係に似ていると思う。一見すると別物だが、検索モデルと生成モデルをシステムレベルまで含め俯瞰的に比較すると、似ている点が多いことに気が付く。
実際、検索サービスを提供する企業は生成AIにも取り組んでおり、検索と生成AIの融合も進んでいる。そのアプローチの一つとしてRAG(Retrieval-Augmented Generation)が有名で研究だけでなく実用面でも人気もある。日常的に利用している人も多いと思われる。
以下、両者をシステムレベルまで含めて、それぞれの目的とその手段(含むアーキテクチャ)で比較する。両者の似ている点と違う点を意識すると、生成AIの理解だけでなく、その将来像も想像できそうである。個人的にはレコメンドシステムとの関連性も見てみたいが、それは機会があれば。
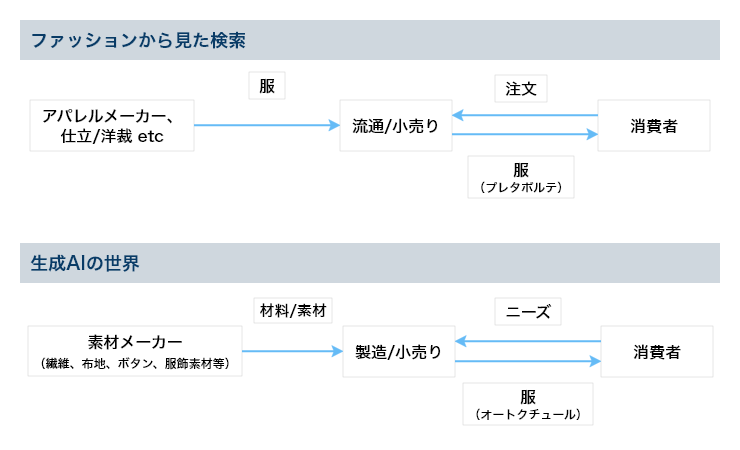
「何か違和感のある図だな」と思われる人は多いと思う。実際、私もここまでデフォルメしていいのか迷ったほどである。検索と生成AIは「Web上のコンテンツ」を用いるのは一緒だが、検索はそれを流通・提供する場所であるのに対し、生成AIはそれを材料や素材として使う工房であるという違いがある。また生成AIでは「Web上のコンテンツ」以外のコンテンツも使っている場合がある。この工房で活躍しているのがLLMsである。
言い換えると、両者ともにユーザの入力に応じ、結果を返す点で目的は一緒。検索はWeb上のコンテンツの場所のリスト、生成AIは生成したコンテンツを提供する。一般的に、検索と生成AIでは同じ対象データ(前者では検索対象/後者では生成AIの学習用データ)を用いた同じ入力に対する結果は異なってくる。例えば、現実世界で「AIについて教えてください。」と質問した際に、「この棚のどっかにあるはずだから自分で調べて」「この本に書いてあるよ」と場所を答えてもらう場合と、「AIの用途は〜」と内容を教えてもらう場合が考えられる。この例では前者が検索、後者が生成AIに相当する。ニーズにより、前者が良い場合もあれば、後者が良い場合もある。そのため、最近は両者を組み合わせたRAGの研究も盛んで、それを用いたツールやサービスも提供されている。前者は仲介、後者は生成という違いがある。テキストを対象とする生成AIは後ほど見るように、既存のコンテンツからテキストを抜き出しているのではなく、一旦トークンに分割し、合成してコンテンツを生成する。音楽が好きな人であれば、サンプラーを連想するかもしれない。結果に集合知が反映される点も似ているが。検索はハイパーリンク構造などの情報が集合知で、それが検索結果のランキングに反映される。生成AIは(対象の)コンテンツをトークンに分割し、トークン単位で分散表現を学習し、その表現を用いコンテンツを生成する。そのため、生成AIは集合知がトークンの分散表現(embedding)、及びそれに基づいて生成されるトークンのシーケンスである(結果の)コンテンツに反映される。従って、集合知が検索のランキング、生成AIではトークンの分散表現に反映されていると見ることができる。
結果のカスタマイズについて見てみると、検索ではクエリの変更ぐらいしか手段がないが、生成AIではpromptの工夫だけでなく、そのベースであるLLMの事後学習やRAGとの併用と手段が多いという違いもある。
正統伝承者とDecoder
ここでは生成AIの代表的なモデルであるLLMの入口のEncoder(Tokenizer)と出口のDecoderについて見てみる。
■Encoder(Tokenizer)
前回の「単語(トークン)」という表現が気になった方もいると思う。LLMsはTokenizerを使って、入力がテキストであればトークンと呼ばれる単位に分割する。結果的にトークンが我々から見て「単語」相当である場合もあれば、「単語の一部」であり、「単語」とは呼び難い単位になっている場合もある。この処理はLLMを学習(訓練ともいう)させるときも、学習済みのLLMを使う(推論ともいう)ときも一緒である。具体的なテキストをトークンに分割すると以下のようになる。
- text = "ルパンの愛車は"
- # tokenize
tokens = tokenizer.tokenize(text)
print(tokens) - ['_', 'ルパン', 'の', '愛', '車は']
「愛車は」は「愛車」と「は」に分かれると思ったのに、意外。特定の目的、例えば商品名やID、業界用語などLLMにトークンの単位として認識してほしい場合、Tokenizerに追加して以降のLLMの学習でそれらの分割されたトークン毎の分散表現を学習することも可能である。これがLLMのインプットとなり、分散表現に変換され、それらの値は学習により更新される。トークンの種類が十万あれば、十万種類のトークンとその分散表現のテーブルが作成され更新される。
■Decoder
DecoderはLLMで学習あるいは推定されたトークン毎の内部表現をトークンに変換し、LLMのアウトプットをトークン毎に出力する。もう少し詳しく言うと、「LLMはインプットのテキストをトークン単位に分割したように、アウトプットもトークン毎に生成する。その生成は最初のトークンから順々に出力する。」この出力はLLMの学習と推論でも一緒である。一子相伝と言いながら、実際は結構な数の伝承者がいる拳法があるそうだ。LLMsでもトークン毎に「それまで出現したトークンの流れを汲む伝承者となるトークンの候補者」が存在する。その候補者、トークン全種類についての分散表現のテーブルの中から確率的に最も高いトークンが正統伝承者?となる。この確率は元々、学習に用いたデータから出てくるが、パラメタを用いて制御することもできる。
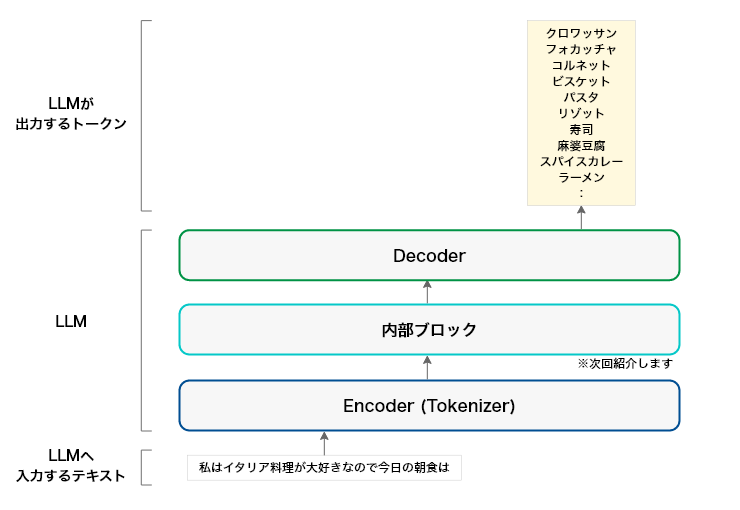
(GPT-2等のDecoderタイプのモデルは上記のEncoder相当(Embedder)を含めてDecoderとなります)
自身でLLMsを利用した方は、「同じ単語あるいは助詞や冠詞などの頻出単語繰り返し」という経験があると思う。そのような単語出現の可能性を制御するパラメタがある。上の図では、このパラメタを変化させることで、全トークン(Tokenizerにより数万から数十万種類になる)についての分散表現のテーブルを参照し、「クロワッサン、フォカッチャ」だけでなく「コルネット、ビスケット」などがトークンとして出現する可能性が高くなる。
この制御可能なパラメタの一つにtemperature(温度)がある。サンプリングにより任意のトークンが出現する確率と温度の間にどのような関係があるのだろう?物理的に解釈すると、温度は分子運動の激しさと比例関係にあり、温度が低い場合、分子の動きはほぼ停止する。このアナロジーで言うと、分子の運動エネルギー分布が全トークンについての確率分布になる。従って、温度を上げれば、この確率分布が一様分布になり、トークンがランダムに出現し易くなる。温度を下げれば、元の確率分布に従い、あるいは分布が急峻になり、トークンは分布に限りなく忠実に従って出現、確率の高いトークンが出現するようになる。出力の安定性ということであれば、この温度パラメタを低くすることも取りうる手段である。
この物理的解釈がしっくりこない人もいると思う。自分の場合は「温度が高くなる→豊作→食料品や食材の価格が安くなる→料理の選択に困ってしまう→どの料理も等確率で選択される」、「温度が低くなる→不作→食料品や食材の価格が高くなる→料理の選択が限定される→料理を選択する確率が一部だけ高くなる」と解釈している。
このトークンについて確率分布(以下、特に断りがない限り確率分布と表記)は推論で入力されたテキストだけでなく、学習で利用した対象データに依存する。Decoderがt番目に参照する確率分布はそれ以前に出現したトークン(最初からt-1番目までに出力したトークンのシーケンス)により変化するので、t-1番目に参照した確率分布とは異なる。もちろん、出現したトークンが異なれば、同じt番目でもその時点における確率分布も異なる。トークンの確率とコンテキストだけでなく、対象データの重要性も実感できる。振り返ると検索ではインデックスとランキング、生成AIではトークンとその分散表現がアウトプットの質に大きく影響する。
検索をプレタポルテ、生成AIをオートクチュールに例えていたが、この例だけでは「なーんだ、ばらしたものを成形(トークンの連結)したものなのか、だったらばらす前と違うものだ」と著作権やhallucination(幻覚)といった生成AIのリスクが伝わらないリスクがある。ファッションでなく、グルメではどうだろうか?例えば、魚を例にとると、検索は魚の取れる場所や魚を売っている場所を教えてくれるが、生成AIは魚を素材に料理を提供する。料理が刺身の場合はどうだろう?魚はカットされているが、ほぼ原型あるいはその一部分をとどめている以上、「全くの別物です」とは言い難いのではないか。生成AIのアウトプットにはこうした著作権だけでなく、その安全性の問題も意識した方が安全である。現実世界ではタラだと思い食べてみたら、実際はオヒョウやメルルーサだったりするかもしれない。白身魚のフライとして提供されたら、区別するのは難しそうだ。同じ白身でもバラムツやアブラボウズだったら大変である。これが生成AIの世界ではhallucinationに相当するので、ファクトチェックは大事である。生成AIにはフグやオニダルマオコゼなど料理人でないと料理はおろか触ることも危険な魚を調理して、提供する相当のメリットもあるが、コンテンツには提供される料理と同じような安全性の問題というデメリットがある可能性も意識しておきたい。
生成AIにおけるLLMs(PLMsも含む)
あらゆる用途やドメインでそのまま使えるLLM、究極のLLMは誕生するのだろうか?「全ドメインかつ最新のコンテンツを、用途を反映したタスク群を設定して学習する」ことができれば、可能かもしれない。その場合、コンテンツは収集して終わりでなく、その品質やアップデートも欠かせない。実際、モデルの進化に止まらず、さまざまなアプローチが存在する。生成AIの中心にいるLLMsを取り巻く状況はどうなっているのだろう?
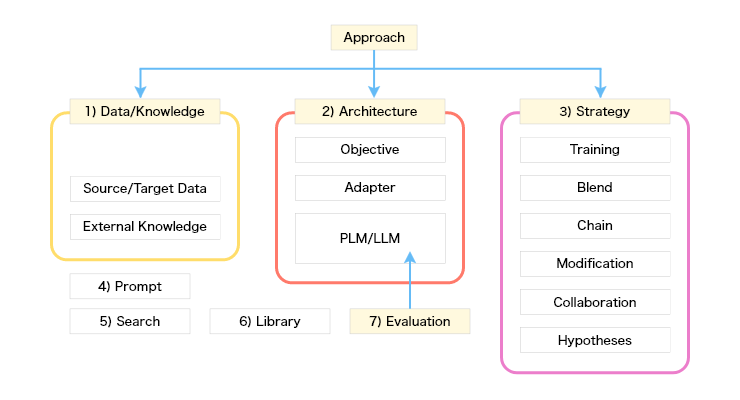
この図を描いてみて、「これは網羅性が高いのか?」「項目は排他的なのか?」と心配の種が尽きない。主にテキスト生成向けのエコシステムを想定したが、LLMsの応用先である画像や音声などマルチモーダルでもほぼ当てはまると思う。
出てくる用語を簡単に紹介すると・・・
- Data/Knowledge:LLMの訓練と強化に用いるデータ。
Source/Target Data:LLMの訓練に用いるデータ。
External Knowledge:LLMには含まれていないデータ(上記以外のデータ)。 - Architecture:LLMの構成要素
Objective:LLMの訓練の目的(タスク)。
Adapter:LLMに追加するレイヤやメカニズム。
PLM/LLM:このテーマかつ話題の中心となる言語モデル。多くの場合、テキストデータを用いて学習、あるいはそれら学習済みモデルを追加で学習する。アーキテクチャ、学習に用いたデータや学習方法により特性が異なる。 - Strategy:LLMの学習や訓練あるいはその利用戦略、手段や仮説がある。
Training/Tuning/Optimization:LLMsの学習、訓練、微調整の手段。代表的な手段には事前学習(Pre-training)、継続学習(continual learningあるいはincremental learning)、Parameter efficient fine tuning(PEFT)、Supervised Fine-tuning(SFT)、Instruction tuning、Mixture-of-Experts(MoE)、 Knowledge Aware Fine-tuning(KAFT)などがある。
Blend:同じ役割を持つ要素(LLM、Strategy、prompt)などの直列な結合。
Chain:同じ役割を持つ要素(LLM、Strategy、prompt)などの並列な結合(Chain of promptなど)。
Modification:LLMのアーキテクチャや学習への追加や修正(Pruning(枝刈り)、Quantize(量子化)、Distillation(蒸留)など)。
Collaboration:異なる要素(LLM、Strategy、promptや人)との協調(Reinforcement Learning from Human Feedback(RLHF)など)戦略。
Hypotheses:LLMの持つ構造あるいはStrategyの方針の元となる仮説。多数決、Lottery Ticket Hypothesis(宝くじ仮説など)がある。 - Prompt:利用者がLLMに与える指示。代表的な指示にはzero shot、few show、in context、roleplayなどがある。
- Search:LLMと検索ツールやサーチエンジンとの融合。RAGなどがある。
- Library:LLMを外から支援するライブラリ(LLMの高速化や画像や音声などをLLMに取り込むためのライブラリ)やプラットフォーム(Flash attention、FlexGen、Petals、DeepSpeedなど)。
- Evaluation: LLMのアウトプットの評価ツールや方法。
繰り返しになるが、これらは分離不可能なものもあり、排他的ではない。例えば、RLHFは人とデータとLLMのCollaborationでありtuningとも見なせるし、promptとtuningを組み合わせた、prompt tuningやprefix tuning、p-tuningなどがある。
これからLLMsはどのように進むのだろう?この図を使って予想すると
- LLM柱:究極のLLMをめざして開発して利用、結果として日でなく月の使い手になるかもしれない
- LLM稽古:自前のLLM開発よりも既にあるLLMsをtuning、組み合わせて利用
- 生成AIの里:LLMsはもう十分、Prompt+RAGで十分でLLMと協力して利用
大きなモデル、LLMsは可能性を秘めている。当初は入力したテキストに続くテキストの予測や生成だったのが、今では入力したテキストの内容や指示を理解し、それに応じたテキストまで生成する創発性を持つのだから。モデルの規模が大きくなれば、Deep Learningの世界では昔から使われてきたモデル学習手法であるDropoutが効いてくる。Dropoutは過学習を防ぐだけでなく、アンサンブル学習、言い換えるとモデル内部で複数のモデルを学習しているような効果が期待できる。また宝くじ仮説で言われるように、元のモデルよりコンパクトなネットワーク構造(モデル)が見つかれば、LLMのダウンサイジングに繋がるかもしれない。RAGによりLLMsで利用するExternal Knowledgeをコントロールすれば、著作権やhallucination(幻覚)のリスクも利用者側で軽減できるかもしれない。データマイニングやBig dataではデータに価値を見出してきたが、生成AIではデータから学習したネットワークやモデルに価値を見出していると言えるかもしれない。まだまだLLMsの成長は続きそうだ。
話をファッションの世界に戻すと、創業時のコンセプトと創業メンバが変わらず、自社農園やアトリエを持ち、全ての人材育成を自前で行っているブランドはどれぐらいあるのだろうか?流行に応じてコンセプトもデザインも変わるし、転職してくる人もいれば、ヘッドハンティングで退職する人もいるだろう。職場が業態変化したり、買収されたりすることもある。ファッション同様、流行に敏感で移り変わりの激しい生成AIの世界でも、モデルだけでなくデータや技術者や環境も全て自前で揃えて一気通貫で対応するのはコストが掛かりそうだ。また流行に合わせてLLMを常に最新化することは誰でも気軽に出来そうもない。目的がLLMの開発ではなく、用途やドメインに合う生成AIの開発や利用であれば、Data/Knowledgeだけでなく、Strategy、PromptやLibraryとの協力が必要なので、多くの場合2)そして3)のアプローチを取ることになるのではないかと思う。
前回からだいぶ時間が経ったので、連載が打ち切りになったと思われる方もいらっしゃると思います。待っていてくれた皆様、今回の記事が出るまでにご尽力いただいた皆様、この場を借りて御礼申し上げます。次回は「生成モデルと検索モデル(後編):昔のことが忘れられないの」、もっと早く公開できるように致します。
川前 徳章 [かわまえのりあき]
エバンジェリスト
(データサイエンティスト)
2009年NTTコムウェア入社。大規模データの分散処理基盤の調査・導入から始まり、レコメンドシステム、情報検索、機械学習、自然言語理解と生成、AI等データサイエンスの研究開発とその導入に従事。現在は生成AIやマルチモーダルに向けたAIの研究開発を行っている。
各種データサイエンスに関する講演など対外的な活動も多く、KDD2021-、ICLR2022-、NeurIPS2021-、ICML2022-、AAAI2024-、WSDM2024-等のトップカンファレンスのPCや査読委員など、国内外でAIやデータサイエンス系の論文審査委員も多く担当している。2023年9月より上智大学大学院 非常勤講師も務める。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
ビジネスインキュベーション本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える