

Coolと最初に感じた人工物の一つはコンコルドだった。そのため、最初に意識した職業がコンコルドの航空機関士だと思う。その後にCoolと感じたのは、ベルニーニのアポロンとダフネ、500系といずれも今から見れば古いアートである。アポロンとダフネは初めて見たときに、圧倒的なCoolさに動けなくなり呼吸も止まり自分も石になったと思った。情報科学であればAlias methodとLocality Sensitive Hashing (LSH)、ニューラルネットワークであればTransformerなどがある。
GPT系列を含むLLMはTransformerと呼ばれるニューラルネットワークをベースとするモデルである。ニューラルネットワークのモデル進化の歴史は勾配の利用と戦いの歴史でもあり、そのモデルの最新形態の一つがTransformerである。今回はその壮大な歴史と、TransformerのCoolさについて眺める。この記事ではさまざまな関数(損失関数、誤差関数、目的関数、評価関数)が出てくるので、どの関数なのか迷わないように注意して欲しい。
ニューラルネットワークと関数
ニューラルネットワーク(以下、ネットワーク)は、ノード(ニューロン)とエッジ(結合)を微分可能な演算を用いて連結した構造を持つ。ノードの集合は層と呼ばれ、一般的なネットワークは入力層、隠れ層、出力層の三つから構成される。各ノードには演算、各エッジには重みが割り当てられる。ネットワークの入力層にデータ(数値)を入力すると、その数値は隠れ層を通じて重みと演算により変換され、出力層から出力される。変換には線形変換と非線形変換があり、このように入力層から出力層までの計算は順伝播と呼ばれる。実行して欲しいタスク、例えば「データの分類、データからの予測」といったタスクであれば、ネットワークは入力データから分類に必要な数値や予測値を出力する。図にしてみると、ノード間の結合はそのエッジを用いた行列、ネットワーク全体は関数で表現できることがわかる。関数及び演算が「加算」及び「乗算」であるネットワークの順伝播を計算グラフで表現し図1に示す。
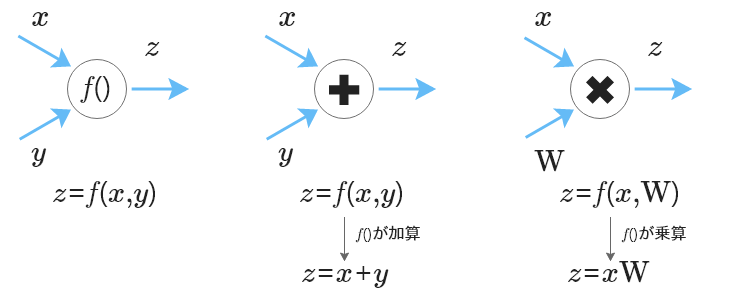
図中のx, y, zはベクトル、f()は関数、Wは行列、演算の形状を揃えばテンソルにも適用できる。f()には加算及び乗算だけでなく減算、除算あるいは指数関数、対数関数や三角関数なども適用できる。これら関数や演算を組み合わせてネットワークは構成される。
ネットワークの設計、具体的にはノードあるいは層の増加、エッジの結合パターンあるいはノード内部の演算を変更することで、ネットワークが実行できるタスクの種類や性能は変化する。ネットワークの代表的な構造、いわば型にはMulti-Layer Perceptron (MLP)、Convolutional Neural Networks (CNN)、Long Short Term Memory (LSTM)、Transformerがある。MLPは基本的な構造で、複数の層と各層の間の全結合の重みを持つ。CNNは畳み込み層とプーリング層を導入し、局所的な特徴の抽出性能に優れ、画像認識のタスクでその能力を世間に知らしめた。LSTMはRecurrent Neural Network(RNN) を拡張したネットワーク構造で、ノード間の時間的順序にゲートと呼ばれるメカニズムを導入し、シーケンスデータのように時間的順序でデータが並んだ一連のデータ内で時間的に離れたデータの間に存在する影響、いわゆる長期的な依存関係の学習に優れているため、時系列データや自然言語処理タスクでよく使われた。テキストを100個のトークンから構成されるシーケンスデータ、トークンをノードに対応させると、100番目のトークンは直前の99番目のトークンだけでなく、それよりも前にある50番目あるいは1番目のトークンの影響が強い、後から出てくる表現を使うとトークンの重みが大きいことがある。これらネットワーク構造の違いは入力データと入力層の役割の違いに現れる。MLPでは入力層の各ノードが「データの属性」、CNNでは入力層のノード全体が「データの構造」、LSTMは入力層の各ノードが「データの時間的順序」と対応する。
自然言語処理のタスクにネットワークを利用する場合、入力データとなるテキストは単語あるいはトークン単位に分割され、その分割単位がノード毎の入力単位になる。TransformerはAttentionと呼ばれるメカニズムを導入し、トークン間の依存関係と同時にトークンのembedding(分散表現)を学習する。この依存関係はAttentionと併用するMask及びAttentionの適用範囲により変化する。Maskの適用範囲には主に1)PAD(バッチで入力データの長さを揃えるために追加するトークン)をスキップする、2)時間的順序で後のトークンを隠す(計算はするものの最終的には利用しない)がある。AttentionにMaskの2)を適用することで、Transformerは任意のトークン列に対し時間的順序が後になるトークン列を生成できるように学習する。LLMの学習(学習の主体がLLMなので訓練の方が適切かもしれない)の目的が「LLMは入力されたテキストからそれに続くテキストを出力する」であれば、LLMの学習は「ある時点のトークンの出現を、未来の情報(時間的順序でその後に出現するトークン)を使わずに、その時点で出現したトークンのみを用いて予測」できるように、大量のテキストデータを与え、LLMのネットワークのパラメタとトークンの分散表現を更新する。「何故、未来の情報を使わないのか?」それは予測を目的としたTransformerやLLMが「未来の情報」を使い学習するのは、カンニングみたいなものである。カンニングしたLLMは学力が身に付かず、本番のテストで実力を発揮するのが難しくなる。Attentionの適用範囲にはEncoderあるいはDecoderそれぞれの入力データ内あるいは、EncoderとDecoderそれぞれに入力された異なる入力データ間の場合がある。前者はSelf-Attentionと呼ばれテキスト生成モデルに利用され、後者はCross-Attentionと呼ばれテキストの翻訳モデル(例えば日本語->英語)などに利用される。
誤差逆伝播法を用いたニューラルネットワークの学習
ネットワークは設計したらすぐにタスクに適用可能な性能を持っているのだろうか?言い換えるとネットワークの重みは初期値のままで十分なのだろうか?「予測誤差が小さかった。もうネットワークはこのまま使える」であっても、データが変わればその性能が持続するか分からない。石でさえ風雨に晒され風化しやがて砂となる。別世界の話だが、鬼退治というタスクに対しても、桃太郎でも柱でも成長や稽古などの訓練は必要である。
LLMはPre-trained Language Model (PLM)とも呼ばれ(ていた)、大量のテキストデータから事前に学習、ネットワークの重みは最適化されている。例えば、GPT系列のようなLLMは与えられたテキストに対してテキストを生成するように学習されている。そのためLLMは汎用的なタスクにはそのまま適用されている。それを別タスクや専門的なドメインに適用する場合、下流タスク(Downstream tasks)を用いた事後学習(fine-tuning)や転移学習が必要になることもある。
ネットワークの学習は、Loss function(損失関数、誤差関数、目的関数とも言われる)を最小化するために、ネットワークのエッジの重み(パラメタ)に対する損失関数の勾配(導関数)を計算し、その勾配の方向にパラメタを移動させて更新する。学習の目的は、ネットワークの予測値と正解の誤差(損失)を最小化するための最適化、学習のために用意する関数が損失関数である。損失関数がネットワークの学習目標を決定し、最適化の方向性を変化させる。代表的な損失関数として数値予測では平均二乗誤差、分類問題ではクロスエントロピーがよく用いられる。勿論、タスクに合わせオリジナルの損失関数を設計、あるいは複数の損失関数を用いてネットワークを最適化することも可能である。学習したネットワークの性能評価に用いる関数を評価関数と言う。ネットワーク自体が関数と見做せるが、学習と評価にはまた別の関数が必要である。ネットワークも我々と同じように、成長の段階においてさまざまな師(関数)が必要になる。
LLMの学習も損失関数の値を小さくするため、大量のテキストデータを用いてLLMを構成するネットワーク内の重みを更新(調整)する。一般にLLMの損失関数にはクロスエントロピーを用い、LLMが入力されたテキストに対し出力(生成)するテキスト(予測)と期待するテキスト(正解)との誤差を測定する。それではLLMが期待するテキストを生成できるように、LLMを構成するネットワークの重みをどう更新するか。ネットワークが小規模であればサンプリングの手法やAlias methodあるいはLSHが使えるかもしれないが、ネットワークのパラメタ数が数十億もあると、いくら高スペックのマシンであっても更新の計算完了まで時間がかかりそうだ。そこで登場するのが、ネットワークにとっての酸素とも言える勾配である。関数が微分可能であれば関数の勾配を計算できることを意味し、ネットワークの重みの更新を容易にする。
関数の解を計算する方法にニュートン法があり、関数の勾配を用いて最適化を実行する。ニュートン法による最適化は計算コストが高く、複雑なネットワークへの適用には向かない。そこでより効率的な方法として勾配法などの最適化手法が利用されている。代表的な勾配法にはBatch Gradient Descent、Mini-batch Gradient Descent、Stochastic Gradient Descent(SGD)がある。Batch Gradient Descentは全学習データ、Mini-batch Gradient Descentは全学習データからランダムに選択した一部のデータ(ミニバッチ)、SGDではMini-batch Gradient Descentのミニバッチのサイズを1としたデータに対して勾配を計算し、パラメタを更新する。AdaGrad、AdaDelta、Adamなどの手法もある。SGDにより勾配とは逆方向にパラメタの重みを更新することで損失関数を小さくすることが期待できる。この学習により、ネットワークの学習にかかる計算コストを削減しながら、パラメタを更新し、その最適化を実行する。複雑なネットワークが合成関数で記述できるのであれば、この関数は連鎖律(chain rule)を適用し基本的な関数の積で記述できる。LLMを構成するTransformerも複数の関数を組み合わせた合成関数と解釈できる。
ネットワークが微分可能な関数で構成されていれば、その学習はSGDやAdamなどの最適化手法とBackpropagationを組み合わせて実行できる。順伝播ではデータがネットワークの入力層から隠れ層を通り出力層から数値を出力するのに対し、Backpropagationは文字通り、順伝播の逆、誤差逆伝播法を用いてネットワークの出力層から入力層に向かい損失関数の勾配を計算する方法である。図1に分岐ノード、損失関数及び逆伝播を加え、図2に示す。誤差逆伝播法の視覚的イメージが欲しい方は、映画だと「TENETテネット」などはいかがだろうか?時間が無い方はJuanes の「La Camisa Negra」のPVが良いかもしれない。もっと時間が無い方はガミラス帝国が開発したドリルミサイルはどうだろう?
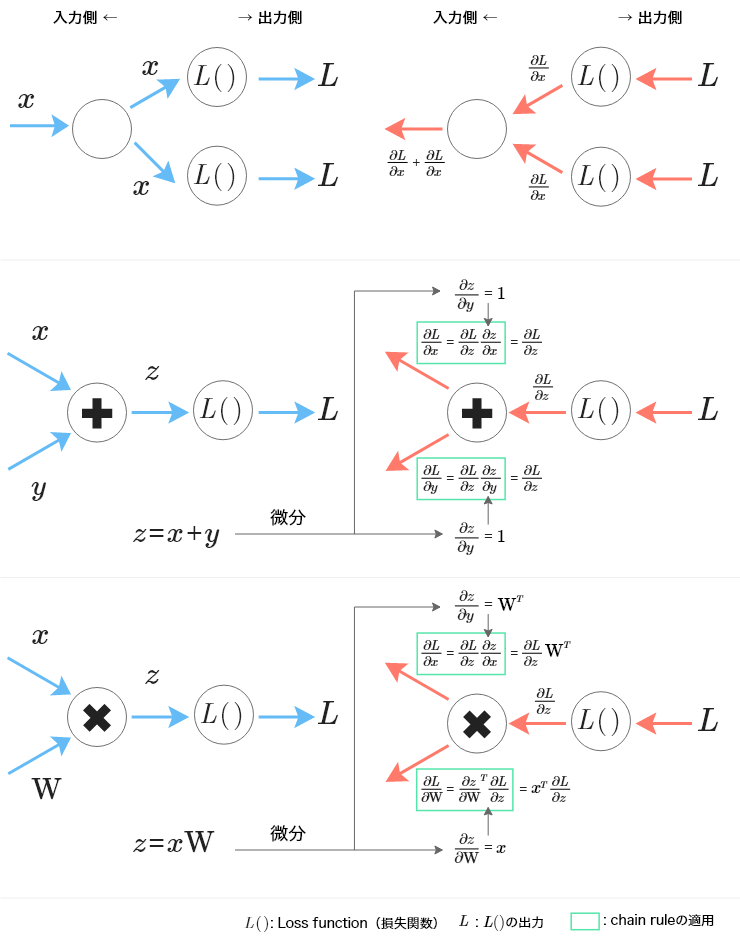
伝播では分岐のノードの出力は入力(出力側の勾配)の加算になっていることに注意する。
Backpropagationは複数の呼吸・・・ではなく関数の勾配の積により深い層のニューラルネットワークの学習が可能になり、複雑なネットワークの活躍の場とそれらを対象とするDeep learningの世界が広がった。ネットワークの学習にとって勾配は我々にとって酸素のようなものではないか。ならば誤差逆伝播法は一連の呼吸をつなげて、勾配を用いて重みを更新する、まさにはじまりの呼吸法とも言える方法である。図2のWは以下のように更新できる。

ネットワークが複雑になる、具体的にはネットワークの層が増えた(深いとも言われる)場合、勾配消失や爆発問題が発生する。ネットワークが微分可能な関数の積で表現できるということは、ネットワークのどこかで勾配が0に近ければ、そこから先(ネットワークの入力層に近い方)の勾配も0に近くなるということである。そのためネットワーク内で勾配が消えてしまう、勾配消失が起き、勾配を伝えることができない。その結果、パラメタの更新がほとんど停止してしまうことでネットワークの学習が停滞する。一方、勾配爆発は勾配が大きくなり過ぎることで最適解を通過してしまい、学習に要する時間(計算コスト)が増えてしまう。終電間際に自宅(最適解)に帰ることを想像してみる。電車の中で寝過ごして自宅の最寄り駅を通過するのが勾配爆発、終電が最寄り駅手前で終点となるのが勾配消失と置き換えると、どちらも自宅に帰るのに追加コスト(この場合も時間やお金)がかかる。この問題の解決あるいは軽減策として活性化関数、バッチ正規化、layer normalization 、residual connectionなどが提案されてきた。
Transformerと勾配消失問題
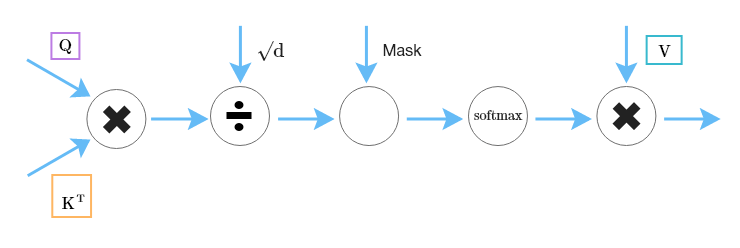
TransformerとLSTMのネットワークとしての大きな違いは何か。その一つはネットワークの線形性による入力データの時間的順序と依存関係の学習メカニズムの違いにある。時間的順序を学習するためにLSTMはゲートと呼ばれるネットワークのメカニズムを導入したが、Transformerはそれに替えてAttentionを導入した。ゲートには役割に応じた複数のゲートがあり、それらの多くは合成関数のネットワークである。復習を兼ねてAttentionの数理的解釈を図3、Maskを適用した例を図4に示す。
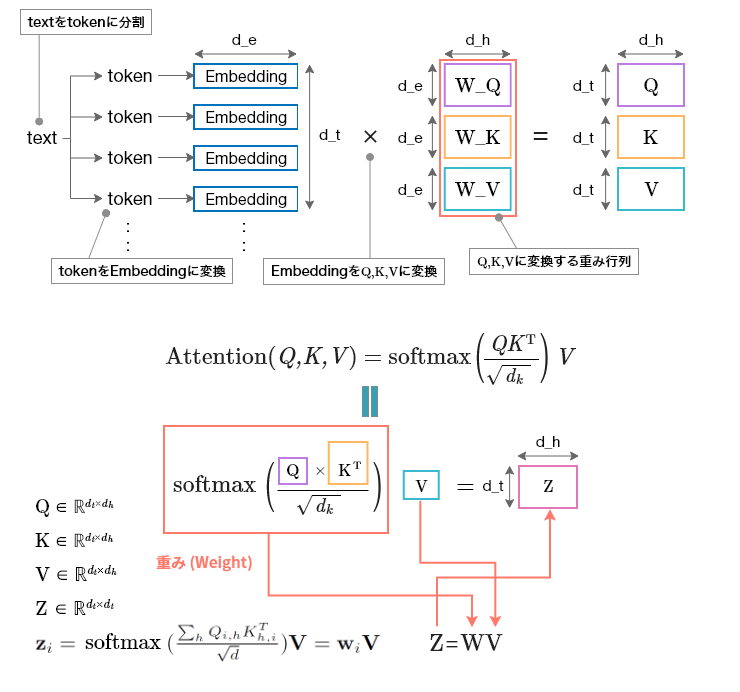
d_eはembeddingのサイズ(数値ベクトルの次元数)、d_tは入力データのサイズ(入力するトークン数)、d_hはネットワークの隠れ層の次元数、Q、K、VはQuery, Key, Valueであり、QとKの転置行列の積は任意のトークンから他トークンに対する重みである。この重みをSoftmax関数を経由しVとの積がAttentionの出力になる。
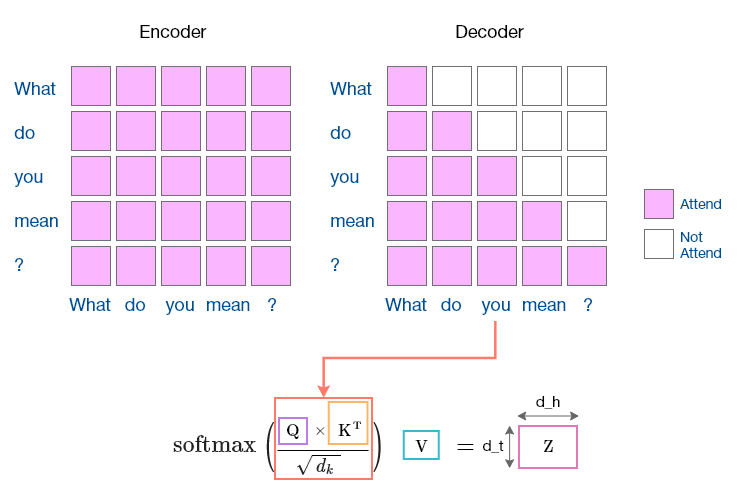
Mask(上)はsoftmax(下)計算前に適用する。DecoderのMaskは時間的順序が後のトークンは参照できない(Not Attend)ことに注意する(Whatが参照できるのはWhatのみであり、カンニングができない)。この図はSelf Attentionの例であり、同じ入力データに対してMaskを適用するため縦と横が同じ入力テキストになっている。Cross Attentionでは、入力データのペアに適用するため、縦と横にはそれぞれ対応するデータ、例えば日本語と英語のテキストになる。このAttentionも図5で示すように微分可能な演算や関数で構成されているため、誤差逆伝播法が適用できる。
AttentionはLSTMにも導入しゲートとの併用も可能である。その場合、ゲートはノード間の勾配を計算するため、入力データの長さが長くなると、それに伴いノード数も増え、時間的順序が前のノードで勾配消失の影響が出てくる。昔のこと(時間的順序が前のノード)を忘れてしまうのである。これではAttentionを導入しても、その相棒であるゲートが忘れてしまうため、結果的にLSTMのネットワーク学習に停滞が起きやすくなる。一方、図3に示すように、Transformerでは時間的順序はAttentionの中で入力された全トークンに対し積とMask(厳密に言えばpositional encodingもある)を適用して学習するため、ゲートに比べ時間的順序方向への勾配消失や爆発は起きにくくなる。図6の赤で示した個所は図2の分岐に相当し、このノードは勾配をそのまま通すため、一方で勾配が消失してもネットワーク全体では勾配を保持できることに注意したい。図3にも示したように、同じ層にあるトークン間には勾配がなく線形結合になっている。そのため、Transformerは昔のことを忘れるというよりは、忘れる時は昔も今も平等に忘れる。
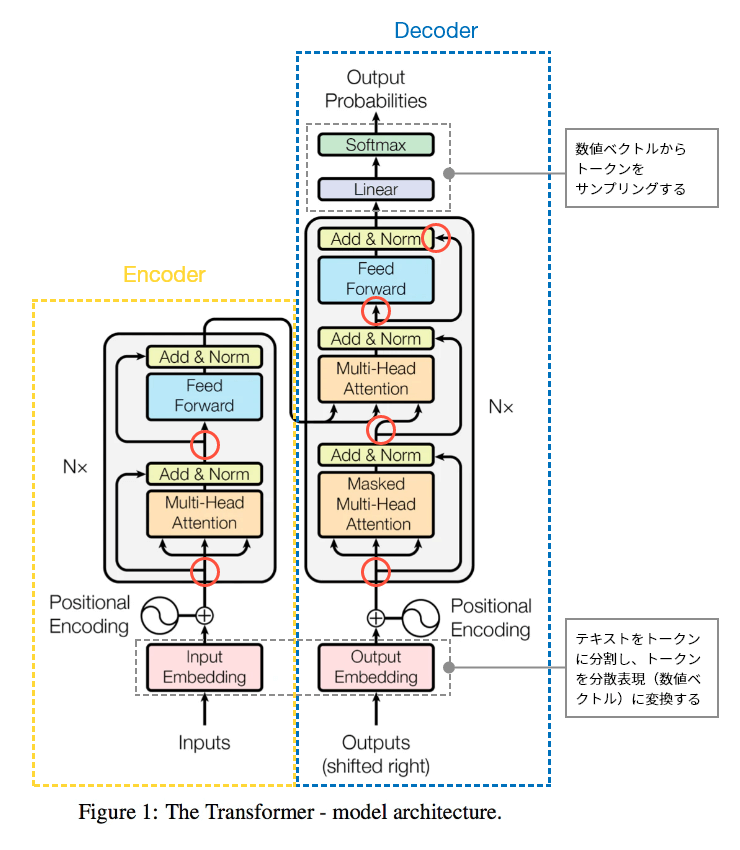
(赤丸、灰点線枠、吹き出し、黄点線枠とEncoder、青点線枠とDecoderを補足的に追加)
図6:Transformerのネットワーク構造
赤丸が分岐になっていて逆伝播で勾配を通過させている。ネットワークにトークナイザがあることで図4のようにテキストをembedding(数値ベクトル)に変換する。その結果、学習ではネットワークの重みだけでなくembeddingも最適化することができる。
ゲートではノードの時間的順序方向に関数の演算が入るので、時間的順序に勾配消失が発生するだけでなく、ある時点のノードが直接連結しているのは直前のノードのみなので、それ以前のノードとの直接的な関係が見えにくくなる。一方、Attentionは任意のノード(ここではトークンになる)からMaskされない(Attend可能)他ノードと直接重み(影響度合い)を動的に決定するため、ゲートよりトークン間の時間的順序だけでなく依存関係(トークン間の重み)を直接記述できるメリットがある。
図5に示すようにTransformerはネットワークの層を時間軸方向に並行でなく、垂直に積み上げた。今度は垂直方向に勾配消失の可能性が出てくるが、layer normalization、residual connectionを導入してこの問題を軽減する。layer normalizationは各層の出力を正規化することでネットワークの学習を安定化させるので抜け駆け防止、residual connectionは各層の入力をその出力に直接加えることで、勾配が層を通過する際の勾配消失を防ぐので、もの忘れ防止をしていると見なせる。residual connectionは他のTransformer以外のネットワーク、例えばCNNや画像生成で話題のStable Diffusionでも使われる。
ここまで線形性についてメリットをみてきたが、表現力や解の探索性ではデメリットもある。線形のノード層をいくら積み上げても、線形演算に変わりなく、ネットワークのパラメタを増やしたのに最適解を見つけられないかもしれない。裏通りや小路に素敵なお店があっても、いつも同じ経路を辿っていては見つけることは難しそうだ。大阪駅の地下街には魅力的なお店が多いが、無限城並みに通路が入り組んでいるため、自分は同じ場所に辿り着くのが精いっぱいで、お店を探検する余裕も無かった。迷わず魅力的なお店を効率的に見つける方法があれば是非とも知りたい。そのために、非線形で微分可能な活性化関数が登場する。「曲がっていいのはコンコルドの機首だけじゃなかった!」と驚かれる方もいるかもしれない。活性化関数と呼ばれる関数は幾つかあり、タスクやデータに応じて選択することができる。代表的な活性化関数にはReLU(Rectified Linear Unit)やSigmoid functionがある。LLMを含むTrasnformerのネットワークの学習ではデータの量や質及び学習方法が大事であるが、この活性化関数の選択やその関数のネットワークでの位置も大事である。大阪駅の地下街のお店探しにも活性化関数が適用できるかはまだ未検証である。
TransformerはAttentionとFeed Forwardから構成されるブロックを積み重ねたネットワーク構成である。Attentionにより時間的順序、layer normalization、residual connectionにより勾配消失や爆発を回避しつつ、活性化関数を用いてシーケンスデータに対して学習を進めることができる。学習させた結果、TransformerのDecoderは第一回で見たようにAutoRegressive modelの関数として振る舞う。大量のテキストから学習させたTransformerは言語理解タスクやテキスト生成において優れた性能を発揮し、その中でDecoderはGPT系列を含むLLMの基盤となっている。改めて前回の検索モデルとの違いと振り返ると「検索はWeb上のコンテンツをハイパーリンク構造などから得られた重みでランキングするのに対し、LLMはWeb上のコンテンツをトークンに分割し、そのトークンをAttentionで得られた重みを基に確率的にサンプリングする」と解釈できる。性能を発揮するためにTransformerは層を高く積み重ね学習し、騒音問題や空気抵抗を回避するためコンコルドは他の旅客機よりも高度を飛行する。
グランドひかり、トワイライトエクスプレスにはどちらも食堂車利用を含めて乗ったことがあるが、500系のグリーン車やコンコルドには乗ったことがない。今でも乗れなかったことが残念でならない。人生には忘れた方が良い事もあるのかもしれない。
Transformerが入力されたテキストの長期的な依存関係を学習できることは、学習データとして用いたテキスト全体の依存関係の傾向、トークン間の重みも学習でき、テキストよりもデータ長が長そうなデータ、例えば音声や画像データの学習にも使われている。前者はpromptやRAGによるテキスト生成に関係し、後者はマルチモーダルへの応用に関係する。
次回はそのpromptによりLLMとのコミュニケーションを楽しむ「Promptが拓くLLMの世界:Promptがうまく言えなくて」です。
川前 徳章 [かわまえのりあき]
エバンジェリスト
(データサイエンティスト)
2009年NTTコムウェア入社。大規模データの分散処理基盤の調査・導入から始まり、レコメンドシステム、情報検索、機械学習、自然言語理解と生成、AI等データサイエンスの研究開発とその導入に従事。現在は生成AIやマルチモーダルに向けたAIの研究開発を行っている。
各種データサイエンスに関する講演など対外的な活動も多く、KDD2021-、ICLR2022-、NeurIPS2021-、ICML2022-、EMNLP2022-、ACL2023、WSDM2024等のトップカンファレンスのPCや査読委員など、国内外でAIやデータサイエンス系の論文審査委員も多く担当している。2023年9月より上智大学大学院 非常勤講師も務める。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTコムウェア株式会社
ビジネスインキュベーション本部
コラム一覧
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える