

生成AIが当たり前の道具になったいま、データサイエンス・機械学習の研究成果をいかに現場の価値へ結びつけるか。「KDD(Knowledge Discovery and Data Mining)」は、その問いに最前線で向き合う世界トップレベルの国際会議である。NTTドコモソリューションズの川前徳章エバンジェリスト(データサイエンティスト)は、2025年8月にカナダ・トロントで開催されたKDD 2025で2本の論文を発表。研究とビジネス応用のあいだに太い橋を架けようとしている。川前エバンジェリストの取り組みがめざすものは何か、そして、それはどのような社会実装に貢献し得るのかについて話を聞いた。
川前 徳章
NTTドコモソリューションズ株式会社 エンタープライズソリューション事業本部
エバンジェリスト(データサイエンティスト)
2009年入社。分散処理基盤の導入から、レコメンド、情報検索、機械学習、自然言語理解・生成などの研究開発と実装に従事。現在は生成AIとマルチモーダルAIの研究開発を推進し、対外活動ではKDDやICLR、AAAI等でプログラム委員・査読委員などを務め、2023年9月より上智大学大学院の非常勤講師も兼任している。
生成AIをどう統合し、どのようにチューニングして“動かす”か
KDDは、コンピュータサイエンス分野の国際学会であるACM(Association for Computing Machinery)が主催し、WSDM(Web Search and Data Mining)やThe Web Conference(旧称:WWW)と並ぶ、データサイエンス分野のトップカンファレンスのひとつと位置づけられている。
同会議の特徴は、学術的な基礎研究にとどまらず、現実の諸問題への適用を強く意識した発表内容が多い点にある。KDD 2025では、研究・応用データ科学・データセットとベンチマークの3領域で論文発表が行われ、グラフニューラルネットワーク*1、レコメンド、セキュリティ、評価(因果推論や施策効果)、マルチモーダル統合*2など、実務に直結する議題が熱を帯びたという。
また、会場では産業分野からの招待講演や実践的なワークショップが開催されたほか、企業のスポンサー出展や採用ブースも活況で、改めて研究と実務の一体感を感じさせる会議であった。毎年恒例のチャレンジ企画「KDD Cup」で、マルチモーダル・マルチターンの「RAG*3(検索拡張生成)」を題材とした競争が行われたことも、その表れだろう。
KDD 2025に分野長(Area Chair)として参画するだけでなく、2本の論文の発表および、「Multimodal Data Processing(マルチモーダルデータ処理)」と「Language Model Applications and Innovations(言語モデルの応用と革新)」のセッション座長(Session Chair)に日本人として唯一任命された川前徳章エバンジェリスト(以下、川前氏)は、今回の会議について「これまでの研究に生成AIをどう統合し、どのようにチューニングして“動かす”かに尽きます」と全体的な印象を述べた。
KDDの研究分野は多岐にわたるが、基本的にはデータマイニングや機械学習を用いて「大量のデータから役に立つ発見を得る」ための技術の研究と捉えるとわかりやすい。すでに「ECサイトで本当に欲しい商品を上位に表示する」ことや「検索の少ない語でも意図を汲む」といったユーザ体験に直結する応用が進んでいるが、近年注目される生成AIのアプローチとの違いについて、川前氏は次のように語る。
「従来の検索エンジンをアパレルにたとえれば、“プレタポルテ(既製服)”を販売する店舗のようなものです。顧客からの注文に対して、大量の在庫から候補を提示して選んでもらう仕組みです。一方、生成AIは素材の仕入れ先こそ同じでも、生地やボタンなどをオーダーメイドで仕立て直してくれる“オートクチュール”のような存在です」
- *1 グラフニューラルネットワーク(Graph Neural Networks、GNN):SNSや交通ネットワークなどグラフ構造のデータを扱うための深層学習技術
- *2 マルチモーダル統合:テキスト、画像、音声、動画等異なる種類のデータを統合的に処理して関連性を理解する技術
- *3 RAG(Retrieval-Augmented Generation):プロンプトだけでは難しいLLM(大規模言語モデル)への指示や情報提供によるLLMの性能を向上させる仕組み
“必要なところだけに賢く投資する”宝くじヘッジファンド仮説と「KADA」
ChatGPTに代表される大規模言語モデル(LLM)は、多くのパラメータ数を持つことによって汎用性を高める一方で、医学・金融・法律など、特定の分野の“専門ドメイン”に移ると途端に回答の精度が落ちることがある。この“知識の偏り=ドメインシフト”(知識分布の不一致)を解消するには、従来はモデル全体を追加学習(ファインチューニング)したり、多数のパラメータを追加する方法で対応したりするのが一般的であった。
ところが、この手法には、モデルがもともと持っている知識が損なわれるリスクや、再学習に伴う計算コストの高さという問題がある。そこで近年は、「PEFT*4」などの新手法が登場している。PEFTはLLMの膨大な既存パラメータを固定(凍結)した上で、特定のドメインやタスクに特化した知識を組み込むための小さな追加パラメータ(「サブネットワーク」や「アダプター」と呼ばれる)のみを更新の対象とするのが特徴だ。
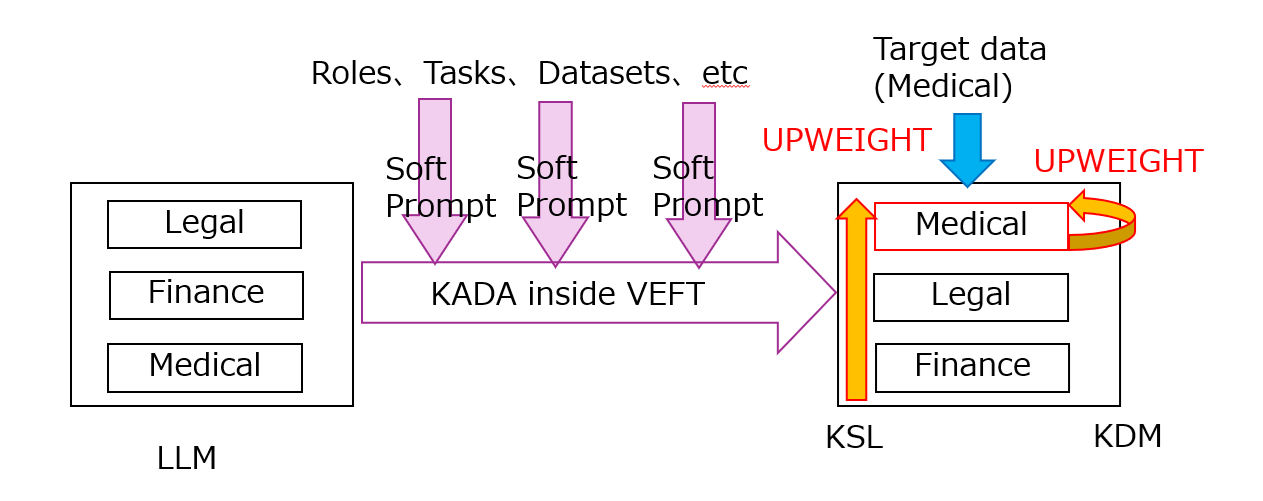
川前氏が発表した1本目の論文では、LLMのドメイン適応としてPEFTに適用可能な「宝くじヘッジファンド仮説(LHFH:Lottery Hedge Fund Hypothesis)」を提案した。LHFHでは汎用的なLLMは複数の専門的知識に強みを持つネットワークで構成されていると考え、それらネットワークの重みを動的に更新することでターゲットドメインに合わせLLMの性能を向上させると仮定する。たとえば、医療分野に適用したい場合、“医療に強い”ネットワークを「投資対象」とみなして動的に重みづけし、関係の薄いサブネットワークの比重を下げるという発想である。
さらに、このLHFHに基づくフレームワークとして提案した「KADA(Knowledge-Aligned Domain Adaptation)」は、モデル全体を作り直すことなく、知識の方向性を合わせるための最小限の調整によって必要なサブネットワークを活性化できる。KADAでは、複数のネットワークを“宝くじ”、その中でターゲットに近い知識を持つネットワークを“当たりくじ”と見立てる。この宝くじの運用をするのが“ヘッジファンドマネジャー”の役割だ。
「個々のネットワークは独立というよりは、大半が同じネットワーク構造を共有しており、その違いはサブネットワークに帰結すると仮定します。ここで知識はあらかじめ絶対的に定義するのではなく、ターゲットドメインに対し、LLMのサブネットワークの重みを再配分して『活性化』することで相対的に獲得されると考えます」(川前氏)
つまり、従来の追加学習のように知識を「加える」よりも、モデル内部の知識を「再配分」するのが重要なポイントだ。サブネットワーク以外のネットワークを凍結(パラメータの更新をしない)することでモデル全体を作り直す必要がないため、訓練時の計算コストを抑えつつ特定ドメインに適応させられる点がKADAのメリットだ。
また、残差効果(Residual effect)の構造を維持し、LLMの基本単位である「Transformer Blocks」の上位でネットワーク層に結合するため、訓練時の誤差逆伝播法*5においてモデル全体の汎用的な能力が損なわれにくい(「破滅的な忘却」*6を回避しやすい)ことも大きな利点と言える。
「KADAは知識の方向性を合わせるための最小限の調整によって必要なサブネットワークを活性化・再配分できます。KADAの調整は動的(入力・ドメインに応じて重みが変わる)、高周波的(素早く適応・更新可能)であり、非侵襲的(基盤モデルを深く変更しない)で最小限の影響で済むプラグインとして提供できることが特徴です。従来のPEFTやMoE*7との併用も可能です。なお、検証はLLMというよりはSLM(Small Language Model)で実施しました」(川前氏)
KADAと同じくLLMに関連する手段であるRAGが外部ドキュメントを検索・参照して回答を補強する「外付けの知識」アプローチであるのに対し、KADAはLLMの持つ汎用性と専門性の両方の特性を効率的に利用することで、内部知識の活性化のアプローチである点も異なる。
つまり、KADAを用いればデータが少ない領域や計算資源が限られる環境でも特定ドメインへの適用を進めやすくなる。これにより、LLMが持つ言語知識(理解、推論、生成)を生かしつつ、企業実務であれば、ターゲットとなる業界用語の多い分野での問い合わせ対応、社内規定に沿った文書作成、社内情報をLLMに反映し、検索や分析ツールと併用し、LLMのドメイン適応だけでなく、既存ツールとの機能連携やAIエージェントへの基盤として導入しやすくなることが期待できる。
「データが少なく、かつ計算リソースが限られた環境でも業務に合わせて、短いサイクルでLLMを訓練できることがKADAの利点です。モデルの凍結はモデルに麻酔をかけるようなもので、KADAは外科というより内科的なアプローチですが、LLMの“華佗(かだ)*8”に成長したら嬉しいです。その結果、散逸したとされる『青囊の書』を現代に蘇生させられるかもしれません」(川前氏)

- *4 PEFT(Parameter-Efficient Fine-Tuning):大規模言語モデル(LLM)を特定のタスクに効率的に適応させるための手法の総称
- *5 誤差逆伝播法(バックプロパゲーション、Backpropagation):ニューラルネットワークにおいて実際の出力を手本となる出力と比較して重みづけを修正する学習手法
- *6 破滅的な忘却(Catastrophic Forgetting):新しいタスクを学習する過程で過去に学習した内容を大幅に失う現象
- *7 MoE(Mixture of Experts):複数の専門家(エキスパート)AIモデルを組み合わせて、特定のタスクに最適化する手法
- *8 華佗は、中国後漢末期から三国時代にかけて活躍した伝説的な名医。「青囊書」は、華佗が著したとされる医学書。麻酔薬の処方や外科手術といった医学的功績をまとめたものと考えられている
履歴ゼロでも“その場で理由とともに推薦”「OSMVR」がユーザ体験を革新する
オンラインのECストアなどで「あなたに合いそうな商品」を勧めるレコメンドは便利な機能である。しかし、初めての利用者には好みの履歴がないため、利用者に合った推薦が難しく、推薦の理由も不明瞭になる問題があった。
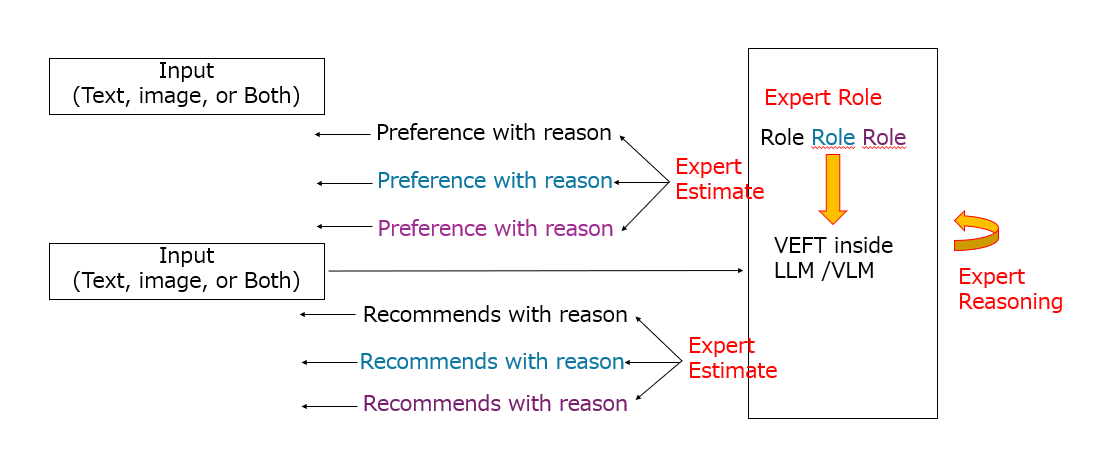
川前氏がKDD 2025で発表した2本目の論文では、この「コールドスタート*9問題」を一度の短い対話だけで解消するための手法として、視覚言語モデル(VLM)を用いたフレームワーク「OSMVR(One-shot Multi-view Visual Conversational Recommendation)」を提案した。
OSMVRのポイントは、VLMの推論力を生かし、ユーザ履歴が乏しい状況でも「好きなアイテムの写真」やヒントとして与えられる短いテキストをトリガーにして、ドメインに対応した複数の専門家の視点から“ワンショット(ひとつの例)”で嗜好を推定し、その場の短い対話でおすすめを絞り込めることにある。言い換えると、ユーザの嗜好の推論から推薦に至るプロセスを、直列処理から異なる複数の視点(View)による並列処理へ進化させ、ユーザの負担を下げて満足度を上げることをめざした技術だ。
たとえば、ユーザが一枚のジャケット写真を送ると、色・シルエット・用途・価格帯といった複数の観点から「落ち着いた色が好み」「ミニマルな装飾を好む」といった仮説を立て、複数の専門家(ファッションであればデザイナー、バイヤー、スタイリスト、服飾研究家など)の観点に基づく推薦と「なぜそれを勧めるか」の説明を同時に返せる。これにより、履歴データに頼れない初回利用時でも納得感のある提案ができ、確認のための長いやり取りも減らせることが期待できる。
「ECサイトなどで採用されているレコメンドエンジンは、個人情報を収集し嗜好を推定することによって推薦を行うのが一般的です。OSMVRでは、この嗜好推定と推薦と二段階のフェーズに分け、各フェーズでユーザに理由とともに提示します。嗜好推定では生成AIが少ない情報からユーザの好みを複数ビューで推定するだけでなく、その理由も説明してくれるため納得感が得られやすく、それに基づく推薦でも複数ビューでその理由を提示します。オンプレミス環境で構築することでプライバシーの保護にも役立ちます」(川前氏)
この生成AIを用いたレコメンド機能を実現するために前出のKADAを複数の専門家の知見を反映できるように拡張したのが、「VEFT(View-Effective Fine-Tuning)」である。これは同一LLMやVLMであっても、プロンプトで役割を設定することでマルチビューの視点を反映した挙動を示すことにヒントを得ており、KADA同様LLMだけでなくVLMにも適用可能だ。
少ない入力から、理由を添えて納得できる推薦を出すというアプローチの適用範囲は、ECサイトだけにとどまらない。たとえば、旅行や住まい、自動車など複雑なオプションが存在する商材で、納得感の伴う提案を行うのにも役立つはずだ。また、動画や音楽配信など初回のユーザ体験における“つかみ”が重要なサービスにとって、離脱を防ぎながら満足度を高める方策にもなり得る。
さらに、OSMVRは目の前の世界と対話する“パーソナルアシスタント”に寄与することを川前氏は期待する。たとえば、スマートグラスと視覚言語モデルを組み合わせ、視界に入った対象物と対話やこれまで見た対象から推定したユーザの嗜好から、その場で最適な導線や対象を提案することも可能となる。美術館・博物館であれば、来館者ごとに展示の回遊順をリアルタイムに最適化し、作品解説も来館者の嗜好や興味に合わせて出し分けることもできるだろう。
「OSMVRのデモンストレーションとして、好きな料理の写真をアップロードするだけで、料理研究家、栄養士、フードスタイリスト、ワインのソムリエなどが最適なワインをお勧めし、その理由を説明してくれるシステムを開発しました。今後はスマートグラスと連携してワインの推薦だけでなく、美術館や博物館でのパーソナルアシスタント検証、および推論力を強化した分析特化のAIエージェントの構築をめざしています」(川前氏)
動画を見る - KDD 2025 - One-shot Multi-view Visual Conversational Recommendation
もし、その提案と理由に納得できない場合は、さらに画像を追加したりシチュエーションを言い換えたりして会話を重ねることで、精度とユーザ満足度をより高めることにもつながるという。
- *9 コールドスタート:レコメンデーションシステムにおいては新規ユーザや新規アイテムに関するデータが不足しているためにユーザに推薦できず、アイテムが推薦されない状態
最先端のAI研究とビジネス実装の橋渡し役へ
基礎研究は、単体で直ちに価値になることはまれである。ビジネスにおいて価値となるのは、運用まで見据えた“動く仕組み”の設計にある。川前氏がKDDで提案したKADAは、モデル内部の知識配分を整え、OSMVRは“履歴ゼロでも当てる”体験の設計をめざす。いずれも、ビジネスにおけるKPIとガバナンスに接続されてこそ、初めて意味を持つ。これらのフレームワークは、最新の開発手法であると同時に運用の思想でもある。
「研究から現場までの距離を縮めるには、数式やモデルを導出し実装するだけでは足りません。必要なのは、エンジニアリング力と数週間程度の短いスプリントでPoC(概念実証)の評価基準の設計から運用までを回せる“型”です。一方で、モーダルを拡張した『MLLM(Multimodal Large Language Model)』への展開やKADAやVEFTのさらなる軽量化、学習の安定化、数理解析、サブネットワークの動的拡張にも取り組んでいます」(川前氏)
現在、日本における生成AIのビジネス活用や社会実装が業界に導入された結果、得られた効果だけでなく顕在化した課題があるとすれば、それはどのようなものだろうか。
「これまでKDDなどさまざまな国際会議に参加してきて強く感じるのは、海外では理論的な研究とビジネス実装のためのエンジニアリングが一体化している傾向が強いことです。国内は研究者とエンジニアの距離が海外よりもあると感じています。AIであれば、『動くまで』だけでなく『運用』や『ユーザ体験』まで想像し、デザインしてこそ、初めて社会にとっての価値になると思います。
情報技術は突然登場したわけではありません。サーチエンジンにより情報の検索が容易になったことで“情報の民主化”が起こり、ビッグデータが話題になる頃には“データの民主化”が進みました。そして生成AIによって“創造性と専門性の民主化”が進み、情報自体も生成される時代になったと考えています。この流れを踏まえると、会議の目的がディスカッションなら事前に生成AIと壁打ちをしたり、情報共有のための資料作成であれば、生成AIをファインチューニングするか、RAG用の外部知識としてデータを格納し、プロンプトのテンプレートを共有することで、業務を効果的に効率化できる可能性があります。これが実際にどこまで適用されるか、あるいは適用する際の課題に興味があります」(川前氏)
データサイエンスとAI研究の最前線であるKDDという場から、現場のダッシュボードまでの距離を縮めることが、いまの川前氏の仕事だ。生成AIが“当たり前の道具”になった時代、エバンジェリストには、生成AIに置き換えられることのない理論の語り手・設計者・運用者としての役割が求められる。必要なのは技術力だけでなく、現在から過去と未来を読み解く洞察力だ。次の挑戦は、すでに始まっている。
インタビュー・記事 栗原亮(Arkhē)
2025/12/22







