

世間で最近話題になっている謎と言えば、「生成AIの仕組みはどうなっているの?」あるいは鬼滅の刃の新作アニメで「刀鍛冶の里の場所はどうして鬼に分かったの?」であるようだ。後者の謎は「刀鍛冶の後をつける」ことで解決できそうなため、前者の謎も同じアプローチで解決できるかもしれない。そのような淡い見通しで生成AIの里(仕組み)を以下のルートで理解する予定である。予定なので寄り道やショートカットもありうるし、ゴールに辿り着けないかもしれない。
- 第二回「生成モデルと検索モデル(前編)」
- 第三回「生成モデルと検索モデル(後編)」
- 第四回「Promptがうまく言えなくて。。。」
- 第五回「Promptがうまく使えなくて」
- 第六回「マルチモーダルへの道(前編)」
- 第七回「マルチモーダルへの道(後編)」
- 第八回「RAG」
- 第九回「レコメンド」
- 第十回「生成AI補完計画」
- 第十一回 「Learning/Tuning」
- 第十二回 「AIエージェント」
- 第十三回「Blowin' in the wind」
- 番外地「NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発」
今回は、刀鍛冶ではなく、生成AIの生成過程とそれを定式化した生成モデルの系譜を辿り、生成モデルの中で現在、隆盛を誇るLarge Language Models(LLMs)へ接近することをめざす。
生成AIの生成パターン
生成AIの明確な定義は難しいが、「これができたら生成AI」と呼べそうな基準はありそうだ。その基準にしても技術の進歩と浸透により、年々難易度が上がっていると思われる。ここでは自然言語の生成AIに限定し、その代表的な生成パターン毎に例を見てみよう。パターン毎に我々が入力するインプットとそれを与えられた生成AIのアウトプットの意味的な繋がりが異なる。
1)インクリメンタルな生成パターン(prefix-suffix)
- インプット:
- 新古典主義は
- アウトプット:
- 新古典主義は、その時代の芸術の傾向を、その時代の言葉で表現した言葉
この生成パターンは生成AIのアウトプットがインプットの続きになっている。現在は、我々の目も肥えてしまったため、この生成パターンができても生成AIの基準のハードルを越えにくくなったかもしれない。
2)反応の生成パターン
- インプット:
- 新古典主義とロマン主義の違いは?
- アウトプット:
- 「合理性」を重視するかそうでないかの違い
このパターンではアウトプットがインプットの続きではなく対になっている。この生成パターンは具体的には対話、会話、質問応答(QA)などが相当する。このパターンは実現手段がルールベースからはじまり生成ベースまであるため、歴史も長くお馴染みの人も多いかもしれない。
3)指示に応じた生成パターン
- Translate mosquito into Italian
- Certainly! The Italian word for “mosquito” is “zanzara”.
この生成パターンへの可能性と将来性が高まり、生成AIが注目を集めている。同時に興味・関心は生成AIを実現する仕組みにも向けられている。その仕組みが、Large Language Model(LLM)と呼ばれる生成モデルである。指示はpromptとも呼ばれ、LLMの学習済みの知識を引き出すことができる。promptの設計により、LLMは翻訳のみならず、先のパターンである対話、会話、QAのアウトプットを提供する。つまり、同一のLLMに対してpromptの設計次第で生成パターンだけではなくアウトプットの質も変化させることができる。この例が物足りなく思う人は既にLLMを使っている人かもしれない。そうでなくても「翻訳」の機能を使えばできるので、何が新しいのか?と思う人もいるだろう。実際、この例は簡単な例である。第四回で詳細に入る予定だが、ここでは「LLMがインプットの内容を理解した、あたかも背後でその分野のエキスパートが記述した、と思えるような知識や結果をアウトプットとして出力する」生成パターンに留めておく。
promptをチューニング(学習)すれば、LLM全体のパラメタ更新ではなく、少数のパラメタ更新あるいは更新せずに、LLMから抽出できる知識も変化させることができる。このLLMが生成AIの実体であり、LLMと呼ばれるモデルは複数存在する。
生成AIの生成過程とモデル化
生成AIがpromptに応じてテキストを生成するため、LLMと呼ばれるモデル群には「一括」よりも「逐次型」、言い換えるとトークンを次々にサンプリングすることでテキストを生成するモデルが多い。このテキスト生成過程を定式化するため、次の図で「?」に入るトークンを手前にあるトークンを参照しサンプリングする過程を見てみる。
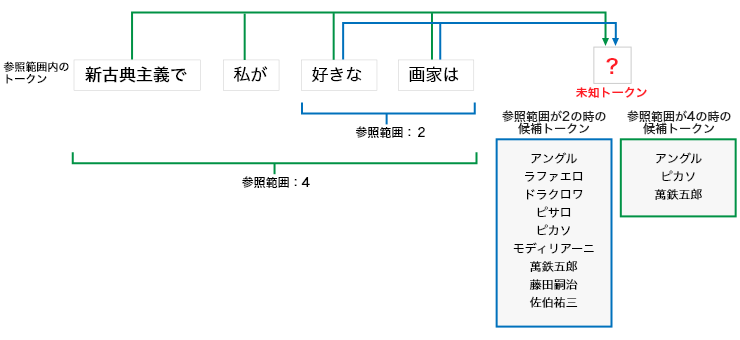
ここで「?」をサンプリングの対象となる未知トークン、サンプリングにより未知トークンに入る可能性のあるトークンを候補トークン、未知トークンまで出現したトークンを参照範囲内のトークンとする。参照範囲は未知トークンを起点とした直前のトークンの範囲で未知トークンに対応する候補トークンは変化する。上の図では参照範囲が「2」の場合、候補トークン内の画家の候補は9名だが、参照範囲が「4」になるとその候補は3名に絞られる。これは人とのコミュニケーションや読書でも、話が進むと、参照範囲も広がることで情報量も増え、その展開が読めてくるという経験があれば実感できるかもしれない。同一トークンでも参照範囲が異なれば、未知トークンへの影響の強さが変化する。例えば、「画家は」は参照範囲が「4」よりも「2」の方が強くなりそうだ。参照範囲内にあるトークンから未知トークンへの影響の強さは異なる。この参照範囲が「4」の例では、候補トークンに対して「新古典主義で」の方が「私が」よりも影響が強そうである。未知トークンが確定すると、参照範囲が変化しなければ、そのトークンを参照範囲に追加して、参照範囲の先頭にあるトークンを除く。この参照範囲に応じて候補トークンも変化し、次の未知トークンも同様に確定できる。この過程を繰り返すと、未知トークンと参照範囲は右側にシフトする。シフトした未知トークンを次々に埋めていくことで、最終的にテキストを生成できる。従って、生成過程のモデル化には「トークンの参照範囲と出現順序」と「参照範囲内のトークンと未知トークンの関係」が必要であることが分かる。
この生成過程の有名且つ重要なモデルが、自己回帰モデル(AutoRegressive model、ARとも略される)である。このモデルは株価や需要の予測だけでなく、レコメンドにも適用できるため汎用性が高い。次はこのモデルを計算機で実行させるために「単語(トークン)の表現」「単語の参照範囲と出現順序」「単語(トークン)間の関係」に加えて「トークンの表現形式」の視点が必要でありそうだ。
生成モデルの系譜
ARを実現するモデルとそれを実行する計算機を用意すれば生成AIはできそうだ。ここでこれまで「生成モデル」と呼ばれたモデル群の系譜を辿ってみる。生成AIを実現するために、計算機上で単語(ト―クン)の「意味を扱える表現の学習」、「参照範囲内での出現順序を反映」、「関係の学習」というエポックメイキングとなる生成モデルの進化があった。以下にこれから紹介する生成モデルの進化の過程を紹介する。
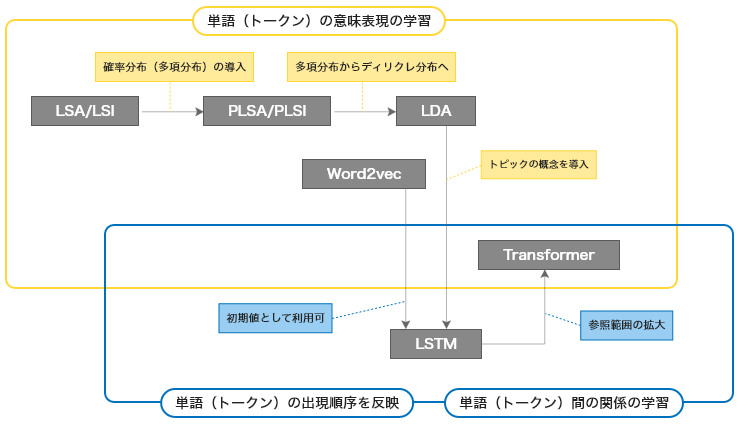
自然言語の生成モデルであれば、「自然言語処理のノウハウ」が詰まっていそうだが、意外とそうでもない。正確に言うと、そのノウハウは人がモデルに直接教えるより、モデルがデータから学習し獲得している。その理由は代表的な生成モデルが、情報検索や機械学習の分野から誕生したことと関係があるかもしれない。
■トピックモデル(LSAからLDAまで)
自然言語処理の分野で提案されたLatent Semantic Analysis (LSA)、情報検索の分野ではLatent Semantic Indexing (LSI)と呼ばれる技術で提案されたベクトル空間モデルがある。この空間モデルは対象となるテキスト集合とそれを構成する単語を、文書と単語から構成される空間から情報損失を最小化しつつ圧縮した空間、概念空間、で表現する。この概念空間内でのテキスト/単語間の点の近さ、それぞれのベクトルの近さが「それに該当するテキスト/単語の意味的な近さ」になること前提とした技術である。従って、テキスト検索をクエリとなる単語の有無でなく、単語とテキストの意味的な近さで検索できることが期待できる。この技術により計算機が単語の意味を扱えるようになった。
その後、LSAに確率分布を導入したProbabilistic Latent Semantic Analysis (PLSA)が登場した。こちらも検索の世界ではProbabilistic Latent Semantic Indexing(PLSI)とも言われる。PLSA/PLSIでは「概念空間」の概念がトピックであると意識されるようになり、トピックと呼ばれるようになった。このトピックの通常の意味とは若干異なり、解析の対象となるテキスト集合を相対的に区別する概念の単位である。各トピックはトピック毎の単語の確率分布で表現され、テキストはトピックの分布で表現される。従って、テキスト集合が異なれば、それから学習されるトピックの分布もトピック毎の単語の分布も異なる。PLSAは観測データ、つまり対象となるテキスト集合のモデル化であるのに対し、Latent Dirichlet Allocation (LDA) は対象となる集合に含まれないテキストも生成できるように拡張されたモデルである。当初、LDAの学習は変分法を使っていた。ギブスサンプリングによる方法が提案されてから、実装が容易になったこともあり、多くのLDAの派生モデルが誕生した。具体的には、マルチモーダル対応、トピックの階層化、トピック数の自動拡張、N-gram等々の対応であり、多くの派生モデルが誕生した。
その結果、LDAは自然言語処理だけでなく、画像処理やレコメンド等へも活躍の場を広げ、Deep Learningが登場するまでは一大勢力を築いていた。この後紹介するDeep Learningのモデルと融合したモデルも存在する。LDA以前のモデルはBag-of-Words(テキストを単語集合として表現するモデル)であるため、学習時点で単語の出現順序を失い、生成するテキストに単語の順序を反映するのは容易ではない。
■LSTM
Deep Learningのモデルでは、最初に画像処理の分野でConvolutional Neural Network (CNN)が話題になり、その次に系列データ(データに時間的順序があるデータ)に向いているRecurrent Neural Network (RNN)、その拡張で単語あるいはトークンの出現順序を記憶するLong Short-Term Memory (LSTM)が話題になった。
ほぼ同じ頃にWord2vecと呼ばれる単語の表現学習のモデルが登場した。LSAと同様、Word2vecも単語をベクトルで表現し、単語間の意味の近さをこのベクトル間の距離で測定できる点は一緒だが、Word2vecで算出したベクトルは加減算しても意味を持つ点が特徴である。有名な事例では、Word2vecで得られた王、男、女のベクトルをベクトル(王)-ベクトル(男)+ベクトル(女)と演算した結果得られたベクトルに最も近いベクトルがベクトル(女王)といった加法性を持った。その結果、単語を意味の足し算や引き算で表現できるようになった。
LSTMとWord2vecで得られたベクトルを併用することで、単語の「意味を扱える」と「出現順序を反映」の両方の特徴を反映したテキストを計算機で生成できるようになった。CNNと併用することで特徴量選択、トピックモデルを併用することでトピックを反映するモデルも誕生した。
■Transformer
元々はencoderとdecoderから構成されるモデルとしてVaswani, Ashish, et al: Attention Is All You Needにて提案された。その論文中で構成は次の図で示されている。
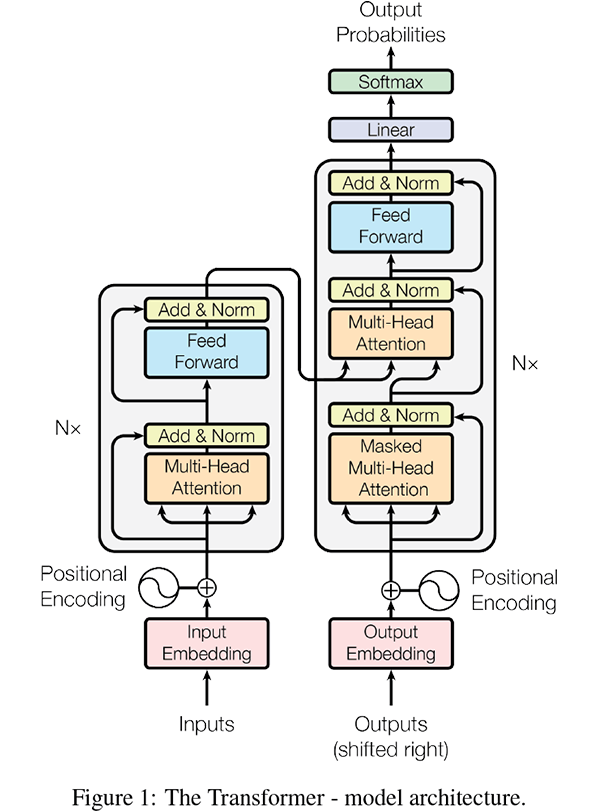
この構成図を見ると、encoder(左側)とdecoder(右側)共にattentionを含むブロックがN回(モデルにより異なる)出現するアーキテクチャになっている。単語(場合によってはサブワードやトークンだったりする)の分散表現がQuery, Key, Valueに変換され、最後は一つになっている。まさに半天狗。Transformer関連の理解はソースコードを見るのが一番早いが、データのフローに関してはこのページが分かり易いと思う。入力テキストを単語に分割するとWord2vecを初期値としても利用できる。
encoderとdecoderの大きな違いは、attentionの参照範囲を定義するmaskにある。encoderは入力単位内での参照を限定しないが、decoderはencoderと異なりmaskによりQueryの参照範囲を限定する。つまり「時刻(順番に読み替えても可)tの単語(Query)が参照できるのは、その時刻t以前の単語(KeyとValue)に限定する」ことでARを実現している。このような制約はモデル学習時の「カンニング防止」をすることでテスト時(推論)に実力を発揮する。カンニングばかりしていたら、本番でカンニングなしに合格はできないだろう。
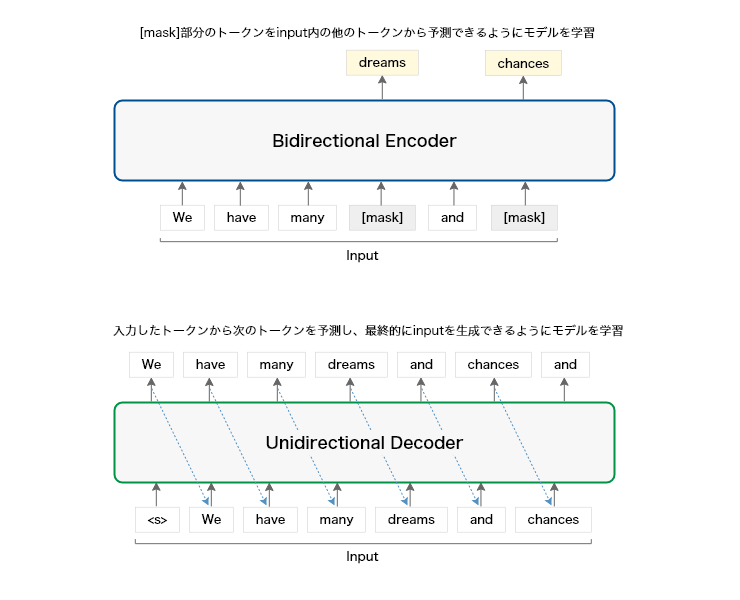
encoderはAutoEncoderにdecoderは前出のARに相当する。従って、前者がCNN(前出のトピックモデル)、後者がLSTMで適用された分野に適用されているのも納得できる。decoderとLSTMの違いは何かということになるが、よりシンプルな構成になったことがあり、その結果、LSTMよりも長い系列データに適用可能になったことがある。言い換えると「単語(トークン)の参照範囲」が拡大し、「その拡大した参照範囲内の単語(トークン)の関係」も学習できるようになった。ここで生成モデルに必要な単語(トークン)の「意味の表現形式の学習」「参照範囲と出現順序の反映」と「関係の学習」の全てが揃った。
Transformerにも当然多くの派生モデルがあり、encoderのみdecoderのみから構成されたモデルもあり、それらにも派生モデルも存在し、層の入れ替えやActivation関数の違いなどがある。
Transformerとその派生モデルが生成AIでの主力の生成モデルであるLLMを占めている理由は、その性能だけでなく、事前に学習されているので(従ってPre-trained Language Models, PLMsとも呼ばれる)、自分でデータを集めてモデルを訓練する必要がなく、ライブラリをインポートする感覚で、直ぐに使えることもある。
はじまりのLLM
Transformerのdecoderをベースにした新たな自然言語向けの生成モデル、LLMの系譜を紹介した論文がある。この後に提案されたLLMも存在するし、今後も誕生するだろう。最近はMetaからLlama 2が発表されている。皆さんは「また新しいLLMが出てきた、もういい加減にしてくれ!」あるいは「今この瞬間にも新しいLLMが産声を上げている・・・浮き立つような気持ちになりませぬか」と思うのだろうか?今のところ、我々が目にできるLLMの違いは「対応できるトークンの長さと種類」及び「それらトークンの分散表現」にある。その違いがアウトプットの違いに反映される。
同じ名前のLLMであっても、モデルサイズが異なるバージョンがあるので、「自宅のPCでも動作可能」なLLMもあれば、「学校や会社で最上位サーバやクラウドでも動かせるか?」なLLMまである。その中から、どのLLMを使うかは目的によって違ってくる。エンジニアであれば「適用ドメイン、既存サービス及びシステムとの相性、カスタマイズの容易性、運用コスト」、研究者であれば「オープンか否か、先行研究でベンチマークモデルになっているか否か、拡張性」等の基準で選ぶことになるだろう。論文等の文献を用いた机上調査で一つに絞り込めなければ、複数を実機検証することになるかもしれない。それで既存のLLMがお気に召さない場合、かつリソースに余裕があれば新たにLLMを作るという選択肢もある。
LLMのメインストリームにいるのはGPTシリーズであり、GPT-2とGPT-3の間で利用形態が大きく変化しているため、GPT-2をここでは「はじまりのLLM」として次回から後をつけてみる。
次回は「生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?」
川前 徳章 [かわまえのりあき]
エバンジェリスト
(データサイエンティスト)
2009年入社。大規模データの分散処理基盤の調査・導入から始まり、レコメンドシステム、情報検索、機械学習、自然言語理解と生成、AI等データサイエンスの研究開発とその導入に従事。現在は生成AIやマルチモーダルに向けたAIの研究開発を行っている。
各種データサイエンスに関する講演など対外的な活動も多く、KDD2021-、ICLR2022-、NeurIPS2021-、ICML2022-、AAAI2024-、WSDM2024-等のトップカンファレンスのPCや査読委員など、国内外でAIやデータサイエンス系の論文審査委員も多く担当している。2023年9月より上智大学大学院 非常勤講師も務める。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える