

NTTドコモソリューションズ株式会社 エバンジェリスト(データサイエンティスト) 川前 徳章
AIは技術革新のスピードを増し、自然言語処理/理解を中心に実用化が進んでいる。なかでも、Q&A対応などで活躍する、人とコミュニケーションするChatbot(チャットボット、以下Chat)は、コールセンターの問い合わせ履歴から自動学習し、実務で人との応答を繰り返すことで、定型的な応答から脱却し、自然なコミュニケーションができるようになってきている。
「データマネジメント2021~データによる可視化が現実と仮想を繋ぐ~」(日本データマネジメント・コンソーシアム(JDMC)主催)での川前エバンジェリスト(データサイエンティスト)の講演をもとに、NTTコムウェアが取り組む、自然言語処理/理解を行うAI活用の最新動向を紹介する。
AIと検索/Chat/レコメンドと、実際の業務との溝を埋める技術とは?
現在、先進企業を中心にAI適用サービスとして注力するのが「検索/Chat/レコメンド」である。なかでもChatは人と機械を結びつけるインターフェースで、機械が人と対話をするためにAIの技術が使われている。
「Chatは、業務自動化のため、(人と接する)応答部分をルールとして記述していましたが、さらなる進化をめざし、ルールで対応できないところは“検索”や“発話自動生成”によって対応するようになってきました。今、これらの技術に注目が集まっています」(川前徳章・エバンジェリスト(データサイエンティスト))
Chatの世界最高水準の技術として、Googleの“Meena”、Facebookの“Blender”の2つが知られている。この2つは「発話自動生成」を実現する技術に相当し、現時点ではBlenderが優勢に立っている。
しかし、これらはコンシューマー向けに作られた技術である。雑談のような受け答えはできるが、企業のヘルプデスクのような、業務知識が必要になる商品やサービスについての比較、判断、レコメンド、使い方を説明するといったことは、そのままではできない。
NTTコムウェアでは、まさにこの部分、つまり、実際の業務との溝を埋めて、業務に使えるように改良していく部分に取り組んでいる。さらに、多くの自然言語のAI関連技術は英語向けであるため、日本語向けにローカライズして提供している。

一致ではなく「意味的に近い」ものを探す、人の思いを取りこぼさない能力
検索およびChatでのAI活用の共通課題として「検索漏れ」がある。
既存の検索システムでは単語をインデックス化し、単語で全文一致検索を行うため、検索できるのは入力した単語に一致した文書のみとなる。この問題をNTTコムウェアは“Embedding”(埋め込み)という技術を用いて解決を図っている。
「“Embedding”では、単語と文書を同時一連続ベクトル空間に”埋め込み”ます。この空間内では、「距離の近さ=意味の近さ」となります。その結果、単語あるいは文書で検索して、意味的に近い単語あるいは文書を検索結果に含めることが可能となります」(川前)
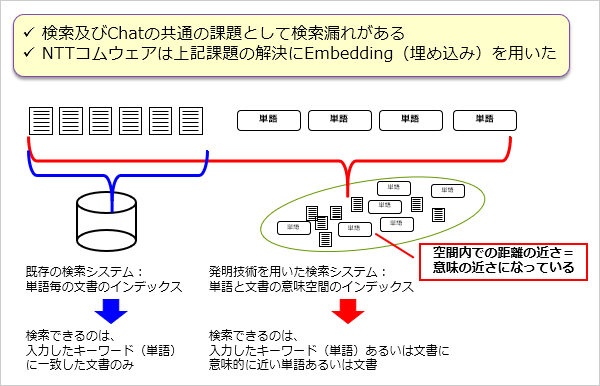
通常Chatのシステムは、Chatの利用者や運用者が用いるサービス提供レイヤーと、サービスの提供結果を元に成長する学習レイヤーから構成されるが、“Embedding”は学習レイヤーで実行する。NTTコムウェアでは、他のサービスと共通で利用でき、かつ、頭脳部分にあたる学習レイヤーをサービス提供レイヤーから独立させることで、運用コストを低減。“Embedding”の導入により、通常のオープンソースの検索エンジンと比較して2倍以上の検索精度の向上を図っている。
現在、NTTコムウェアでは、業務での活用に適したMeenaやBlenderに相当する技術、つまりQ(質問)に対する正解がQA集にない場合でも、正解に相当する内容を発話自動生成する技術の研究開発を進めている。
AIの構成技術とその役割
AI(Chat)をつくり出すには、データの「表現獲得」「対応関係学習」の2つが必要である。
・表現獲得
AIを実現するプログラムにデータを理解させるためのデータ形式を“表現”と呼び、”Embedding”もその1つである。自然言語処理では、テキスト文を単語あるいはそのサブセット単位でプログラムに読み込ませている。
・対応関係学習
参照や引用といったテキストを構成する単語(トークン)間の対応関係を取り出し、例えば「あれ」(代名詞)がテキスト中のどの単語を指しているかと学習する、その仕組みを”Attention”(注意)と呼ぶ。“Attention”では、単語と単語の関係の重み付けにより対応関係を可視化していく。
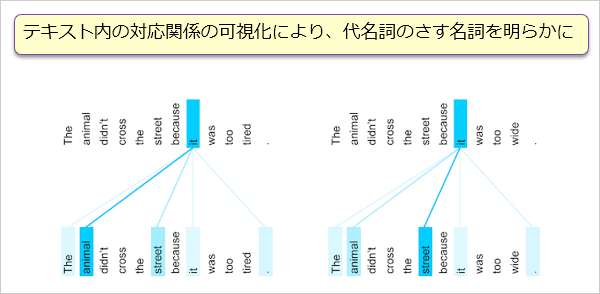
当初、Deep Learning の代表的なモデルとして、MLP、CNN、LSTMが知られていたが、それに続く第4のモデルがTransformerであり、“Attention”の集大成と言われている。Transformerでは単語と単語だけでなく、テキストとテキストの対応まで学習できる。
Transformerベースのモデルのほとんどがオープンソースとして利用可能になっている。下記のTransformerの家系図は2020年のものであり、現在はもっと巨大なファミリーに成長している。
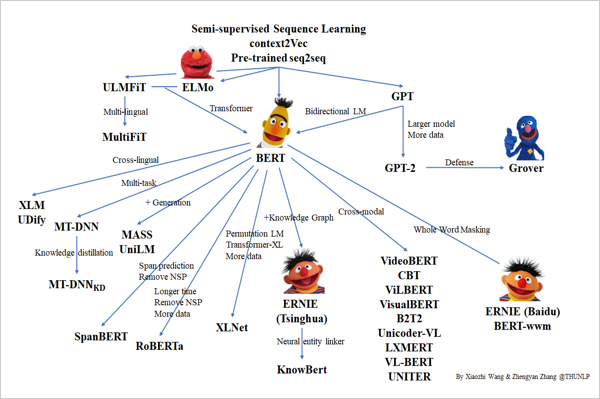
出典:https://github.com/thunlp/PLMpapers
※Googleは、Google LLC の商標または登録商標です。
※Facebookは、Facebook,Inc.の商標または登録商標です。
画像をメタデータ不要で取り扱うMulti-modal、話者の重み付けとは?
さらに詳しくChatのAIについて解説する<後編>はこちら >>




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える