

NTTコムウェアは、NTTグループの加入者情報や料金請求データ等大量のデータを扱うシステムを長年構築・運用してきた。その過程で培ってきた技術をさらに磨き、注力技術領域の1つとして「Data Management」に取り組んでいる。本稿では、AIの種類とBERTの登場をきっかけとした自然言語処理の発展、ディープフェイクの元となる技術、そして、マルチモーダルとコンテンツ生成を中心とした、データサイエンスおよびAI領域におけるNTTコムウェアの取り組みについてご紹介する。
その羊は本物ですか?
データサイエンスと日常生活の接点の一つにAIがある。AIが人間の仕事を奪う、あるいは人間を超える等の議論の結果はいずれ明らかになるとして、現時点で明らかになっているのは、コンテンツ生成に関してはAIが生成したコンテンツと人間が作成したコンテンツの区別が人間に付かなくなっている。
AIの代表的な技術であるDeep Learningは、最初は画像処理の分野で驚くべき成果を出して、自然言語処理の分野まではしばらく時間がかかると言われたが、既に自然言語処理の多くのタスクで実用化のレベルまで達している。
AI(を支える技術、長いので以下AIという言葉に含める)に「羊の絵を描いて」と言ったら、何ができるだろうか?前提として、一口にAIと言っても、AIの学習に用いたデータやその学習目的により、AIにできることは異なる。画像処理に特化したAIもあれば、自然言語処理に特化したAIもあり、両者を処理するAIもある。従って、画像処理に特化したAIであれば、あなたが星の王子様でなくても、羊の絵を描くことができるし、自然言語処理に特化したAIであれば、「星の王子様」だけでなく羊つながりで「アンドロイドは電気羊の夢を見るか?」の感想について会話ができるかもしれない。
具体的に前者のAIを実現しようとすれば、インタフェースに音声認識を置いて、バックで簡単な技術だとスタイル変換、ちょっと凝った技術であればGAN/VAEやFlow-based Model(※1)などを使えば可能である。後者であれば、レビューサイトやSNSから関連する内容のテキストデータを予め収集し、BERT、RoBERTa、XLNet(※2)などのモデルで会話のパターンを学習させて実現する。これらの絵といった画像処理や生成される会話といった自然言語処理のコンテンツの質が、今では一目で人間が作ったのか、AIが生成したのか分からないレベルになってきた。
本物の羊なのか電気羊なのか区別ができないことをAIが実現できる時代になった。驚くべきことにこれらの技術はほぼ無料で、計算機環境があれば、誰でも実現できる時代になった。一方でこれらの技術の多くはネットワークに重みを学習させるタイプなので、出てきた結果に対して説明ができないことが殆どである。「大事な事は目に見えない」という課題がある。
こうしたことがなぜできるようになったのだろうか?自然言語に関してはBERTの登場がある。BERTはGoogleが発表したDeep Learningのモデルである。そのモデルは人間でも文書を理解しなければ実行できない翻訳、分類、感情分析、質疑応答等の自然言語処理のタスクで既存のモデルのスコアを上回るだけでなく、質問応答のタスクによっては「人間」よりも高いスコアを叩き出し、「AIが人間を超えた」と話題になったことでご存知の方も多いだろう。既にBERTはGoogle等のサービスに使われているだけでなく、BERTを超えるといわれるモデルが登場し、自然言語以外の分野にも適用が広がっている。登場して2年も経たないが、現在の自然言語処理はBERTを抜きに語れない。
厳密に言うと、BERTの中核となっているTransformerというメカニズムがこの分野の発展を席巻している。図1にBERTとそのファミリーを紹介する。登場して2年も経たないのにこの大家族。今後もこの家族のメンバは増えていく。江戸幕府の第11代征夷大将軍、徳川家斉も驚くであろう。
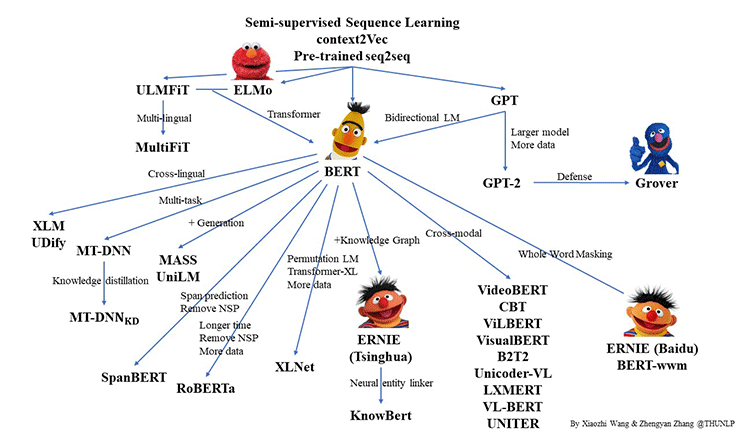
出典:https://github.com/thunlp/PLMpapers
これらのモデルはPre-trained Language Model (PLM)とも呼ばれている。一般で使う場合は、既に学習済みのモデルを使うことが多い。そうでなく、これらのモデルを最初から学習させるあるいはこのファミリーに追加予定の新規モデルを学習させる場合、どのくらい費用がかかるのだろうか?おそらく大企業でいうところの本部長決裁が必要になるくらいかかるだろう。
AIに羊の絵を描かせるなんてリソースや技術の無駄遣いと見る向きもあるが、そんな平和的な利用ばかりでなく、ディープフェイクと呼ばれる、本物との見分けがつかない、かつフェイクであるニュース、画像、動画や音声をAIが生成できることが問題となっている。例えば、選挙での有力候補者のフェイク動画や演説文書が話題になったのは記憶に新しい。そのような背景があり、非営利のAIの研究組織であるOpen AIが発表した文書生成技術であるGPT-2(Generative Pre-Training 2)は人間が書いたような文書を自動生成できてしまうことで悪用されるリスク回避のため、最初はその技術論文やモデルもなかなか公開されなかった。GPT-2は入力された数単語から、その後に続く単語を予測し、文書を自動生成する技術であり、スパム、フェイクニュースやフェイクコンテンツ生成などへの悪用が懸念されているが、最近公開されたその後継モデルであるGPT-3はプログラムのコード生成、楽曲生成、画像生成までできるようになった。
現在、同じことができる技術はGPT-3に限らなくなってきた。ニュースを見ないから関係ないでは済まされない。本人と区別が付かない音声が生成されれば、なりすまし等の詐欺や名誉棄損の被害の規模も今より拡大することが心配されている。一方、こういったフェイクを検出する技術の研究も進んでいる。
データサイエンス/AIの取り組み
~マルチモーダルとコンテンツ生成~
フェイクの話はここまで。これから事実として自社の技術・取り組みを紹介させていただく。
NTTコムウェアではデータサイエンスとAIの応用として、マルチモーダルとコンテンツ生成の分野に取り組んでいる。マルチモーダルとはテキスト、画像、動画、音声といった異種のデータをシームレスに扱う技術の総称である。要は画像処理と自然言語処理のハイブリッドである。
例としてマルチモーダル検索を紹介する。この検索はクエリとして「羊の絵」と与えられると、結果として羊の絵を返す。これだけ聞くと、通常の画像検索でできていることと変わらない。その違いは、通常の画像検索は画像のメタデータや画像を埋め込んだファイル、周辺テキスト、アンカーテキストなどを画像のインデックスとして利用した全文検索の応用であるのに対し、マルチモーダル検索は同じデータを使い、画像から抽出した特徴量とテキストの関連から「この画像は羊の画像である」ということを学習する。その結果、メタデータすら存在しない画像に対しても、画像特徴量を抽出し、その画像が「何の画像か」を理解できるようになる。言い換えると、テキストと画像を組み合わせ、「テキストの内容」と「画像の内容」を同時に学習している。同じフレームワークを用いれば、画像でなくても特徴量が抽出できれば動画や音声などの他種データも検索できる。ここで私たちが開発したマルチモーダル検索の結果を紹介する。データセットはFlickr30k(http://bryanplummer.com/Flickr30kEntities/)データセットを用いた。
通常のマルチモーダル検索のタスクでは、クエリとして入力された自然文に合った画像を検索する。

私たちはさらにクエリとして画像やテキストや単語を組み合わせたときに、そのクエリに合った画像を検索できる技術を開発した。

この上の例では「犬の画像」から「dog」を引くと、犬を他の対象に置き換えて、元の画像と背景が似た画像を検索し、「grass」を引くと、犬が地面を走っている画像を検索できるようになった。この分野に関してはBERTの派生形であるVL-BERT、 ViLBERT、 UNITER、 Unicoder-VL(※3)といった強力なモデルが存在し、先ほどのPLMの家族構成の中でも最も密でライバルの多い分野である。これらBERTの血をひきし者と私たちのモデルの比較、検証を実施中である。
私たちはマルチモーダルと並行して自然言語理解、自然言語生成、及びその延長上にあるコンテンツ生成の研究にも取り組んでいる。この分野ではXLNetや先の図にはまだ出ていないALBERTやT5(※2)などの強力なNatural Language Model(NLM)のライバルが存在する。私たちが取り組むテーマは、個人毎にカスタマイズされたコンテンツの生成であり、その適用先としてECサイトがある。ECサイトには、利用者の商品選択と購入を後押しする機能としてレコメンドがあるが、その購入単価が高くなると、レコメンドの結果だけでなく、購入を検討している商品について、既に購入された他者の商品の「レビュー」を重視することが知られている。こうしたレビューが全ての商品にあるとは限らず、あったとしてもユーザ毎に重視する項目が違うので、自身と重視項目が異なる他者のレビューが役に立たない場合がある。
例えば、出張先のホテルを選択する際に、「立地」を重視するユーザに対して、「部屋の広さとアメニティー」を重視したユーザのレビューは役に立たない。ECサイトはユーザ毎にカスタマイズしたレビューのリストの自動生成を試みるが、既存のNLMを利用すると
1)NLMの事前学習でレビューデータを使っていないので、NLMから期待するレビューが生成できない
2)NLMの事後学習でレビューデータを用いても、そのサイズが小さいと1)と同様にNLMは期待するレビューを生成できない
3)事後学習に十分なサイズのデータを用意しても、ユーザの嗜好などを反映させなければ、各ユーザに合うレビューのリストを生成できない
という課題がある。
そこで私たちは、既存のNLMは追加学習の結果を反映させるにはモデルが巨大で、かつ、個人の嗜好を学習し難いという課題を解決するために、より軽量かつ個人の嗜好に合うレビューを生成可能な自然言語生成のモデルを開発した。同時に、「大事な事は目に見えない」ことはユーザに対し不親切なので、「なぜこのレビューを生成したのか」ということが分かるexplainabilityの機能も提供している。
現時点で、このモデルの検証を商用サイトから収集したレビューデータ(ベンチマークデータ)を用いて完了した段階である。検証において、レビュー生成ではNLMの評価指標であるROUGEとBLEU(※4)でも他のNLMを上回る精度を達成し、並行してレコメンドの根拠となる、ユーザ毎の商品の評点予測においても既存モデルに比較し高い精度を示している。個人に合わせたレビュー生成は主観評価になるが、同じ商品であってもユーザ毎に重視する項目の異なるレビューを生成したことを確認している。
マルチモーダルとコンテンツ生成を組み合わせると、冒頭と同じ例を使うと人間とAIはこんなやり取りをするのではないだろうか?
利用者:「羊の絵を描いて」
AI:「どのようなタッチにします?」
利用者:「どんな絵を描けるの?」
AI:「今だったら、佐伯祐三風かレオナール藤田風ができます」
利用者:「同時代の対照的なアーティストだね。じゃあ、両方描いてもらおうか?」
AI:「承知しました」
この記事はAIでなく人間が作成した。数年後に「あの記事は全てフェイクだった」と言われないように、今後も研究を継続し、皆さまに羊の絵をお見せできる日を楽しみにしている。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える