

カンファレンス概要
ACM International Conference on Web Search and Data Mining(WSDM)はACM主催のトップカンファレンスの一つで、Webやデータマイニングをメインテーマとして扱うカンファレンスです。今年で16回目の開催となり、今回はシンガポールで2月27日から3月3日まで、オンサイト(現地)とオンラインを組み合わせたハイブリッド形式で開催されました。今回、私はPre-trained Language Models (PLMs)(Large Language Models(LLMs))のドメイン適合のフレームワークの論文発表に加え、セッションチェアも務めました。

WSDMの最近の傾向としてACMのKDDと同様に(機械学習の応用分野である)レコメンドやグラフネットワークに関する研究発表が多数を占める傾向があります。今回のカンファレンスでも全9セッション中、3セッションがレコメンドのセッションとなっており関心の高さが伺えました。
WSDMの特徴の一つに、スケジュールがシングルセッションで構成されていることがあります。従って、「この時間帯はどのセッションを聴講しよう?」とスケジューリングに頭を悩ませることなく聴講に集中できます。KDD等テーマが近い他のカンファレンスに比較すると投稿論文数が少なく、それに比例し参加者も少ないため、アットホームな雰囲気、かつ友人や知人も作り易い特徴もあります。今年の開催場所はホテルで、かつカンファレンス開催中は天気も悪かったので、同ホテルに宿泊することでカンファレンスに集中できた参加者が多かったと思います。
発表動向
カンファレンスで発表された論文は昨年の8月に参加したKDD同様にレコメンドに関する研究テーマが多く見られました。グラフマイニング、知識グラフ(Knowledge Graph(KG))、強化学習(Reinforcement Learning(RL))、大規模言語モデル(LLMs)を用いた点もほぼ一緒です。この分野のカンファレンスに続けて参加した方は既視感を感じたかもしれません。
今回に限らず、AIや機械学習の応用を扱うカンファレンスでレコメンドの研究が近年多い理由は、機械学習やデータサイエンスの応用先としての人気の高さやタスクの多様性に加え、それら研究に欠かせないデータ及び既存研究のコード共有や公開が進み、検証だけでなく参入のハードルが下がったことが一因であると思います。
レコメンド実現のアプローチとして、ユーザー間の購入やクリックなどの履歴を用い、履歴間のデータ欠損を補完することでユーザーやアイテムの類似性に基づく協調フィルタリングが有名です。今では履歴だけでなく、ネットワーク、KGそしてテキストまでも用いています。その延長線上にレコメンドがあり、レビューテキストやKGといった外部知識と手元にあるデータと組み合わせるアプローチは、データ結合による知識補完以上の効果が得られ、レコメンドや知識ネットワーク以外の研究でも人気です。モデルやフレームワークの学習方法として人間との機械の対話プロセス等の多様な評価指標を組み込むためにRLもよく利用されています。今回のカンファレンスでもこのトレンドに沿った論文が発表されました。
キーノート
キーノートは3件の講演があり、その中でマルチモーダルの研究紹介が最も興味深い発表でした。発表内容は音楽配信サービス「Spotify」で取り組んでいる研究の紹介でした。その中で楽曲のカテゴリ予測タスクがありました。このタスクは、歌詞と音声の波形データを使い、前者はBART、後者はMLPを用いて最終的に連結したアーキテクチャで実行しています。
聴講して感じたのは「最近の楽曲はプロモーション映像(PV)があるので、それも加えて分析したらどうなるだろう?」ということでした。私の知る限り、歌詞の世界観と映像の世界観がマッチしていないPVが多いので、予測タスクに対してはあまり効果がないかもしれませんが。少し、本筋から逸れますが、その時にマッチングしていない例として何故かDidoのThank you(PVは歌詞よりメロディーに合わせたのだろうか?)を思い浮かべました。それから数か月後、この原稿を書いている時にちょうどその曲がラジオから流れてきました。最近はそんなにオンエアされる曲ではないので、驚きました。
本筋に戻ります。講演からは、現在のマルチモーダルの分野で主流であるアプローチの取り組み状況については分かりませんでした。このタスクであれば「KGの取り込みによる歌詞データの拡張」や「歌詞および音声を同じ表現形式に射影し、contrastive learningでコンテンツ(この場合は楽曲)間の相対的類似性を学習する」というアプローチが可能ではないかと思いました。音声データは画像データよりもテキストとのmodality gapの問題解決が難しいのでしょうか?その点について質問できなかったのが残念です。
表現学習に限らず、対象の類似性の定量化は難しくもあり、興味深い。例えば、楽曲であれば、特徴量として「人の主観的判断」や「曲の波形」を使うことが考えられます。その場合、ドヴォルザーク: 交響曲第9番「新世界より」:第4楽章と「JAWS」のテーマ曲の類似性は前者では高いが、後者では前者程顕著な類似性が見られないかもしれない。これが映画になるともっと難しい。特徴量も難しいが、例えば「人の主観的判断」であれば、「トップガン マーヴェリック」と「ファイヤーフォックス」に適用するとどうなるでしょう?主観的な類似性は個人にも依存するので、客観的な類似性のアライメントにもさまざまなアプローチがあります。類似性の定量化についても多くのアプローチが誕生していくでしょう。
発表論文
今回のWSDMで口頭発表された論文の中から私自身のテーマに近く、かつ興味深いと思った論文を紹介します。
Zhang, Xiaoyu, et al: Variational Reasoning over Incomplete Knowledge Graphs for Conversational Recommendation
会話形式によるレコメンドシステム、Conversational recommender systems(CRSs)の論文です。
CRSsはユーザーの興味関心をユーザーとシステム間の会話を通じて理解するため、その理解に自然言語理解の技術を必要とします。そのCRSsへのインプットにKGを用いるアプローチが提案されていますが、KGには、不完全、疎性、曖昧性といった課題があることが知られています。
この論文はこのようなKGの課題解決に対話データを用い、KGを構成するサブグラフを離散的な潜在変数として表現し、変分ベイズで推定、つまり、元々のKGには存在しなかった関係を明示的に推論するアプローチを備えたシステムを提案しています。
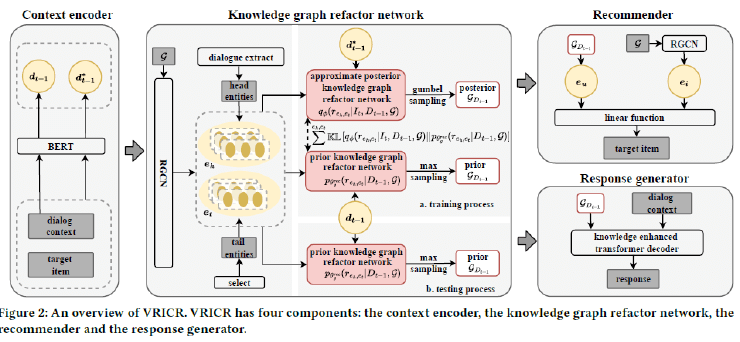
会話履歴やKGから学習するレコメンドシステムは既にありますが、この研究のように自然言語処理あるいはPrompt learningを用いLLMを外部知識として利用するシステムも増えていくでしょう。具体的には両者を並列というより、KGをLLMに追加学習させることで、KGとLLM内にある情報をシームレスに結合して利用する仕様になると考えられます。
Bing, Qingyu, et al: Cognition-aware Knowledge Graph Reasoning for Explainable Recommendation
この論文もKGを用いたレコメンドを扱っていますが、KGの構成要素間の関係構造をアイテム推薦理由の説明生成に利用するだけでなく、認知科学における二重プロセス理論に着想を受けている点が先の論文と異なります。従来の研究は推薦理由を提示するためマルチホップにあるユーザーとアイテムの関係を探索していますが、この研究ではこの探索に用いるアルゴリズムと人間の推論プロセスにギャップがあることを指摘し、それに代り人間の認知過程を模倣する手法、具体的には直感的な推定、及び明示的な推論を実行するモジュールから構成されるモデルを提案し、その全体像を論文中で次の図で示しています。
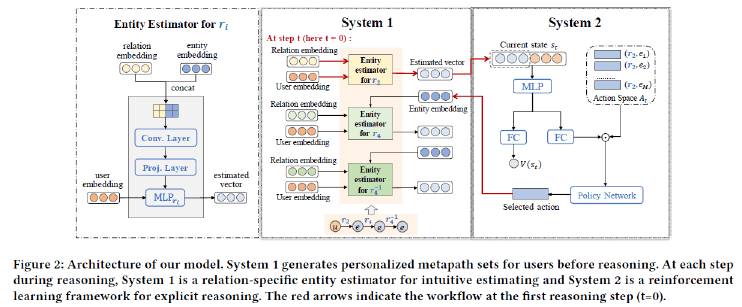
このモデルは、モジュール間でRLフレームワークを用いて反復的に学習し、アイテムの推薦理由を推論します。
Chu, Zhendong, et al: Meta Policy Learning for Cold-Start Conversational Recommendation
CRSは、ユーザーの好みを会話から明示的に聞き出し、リアルタイムでレコメンデーションを改善できるシステムです。既存のCRSの多くは、RLにより訓練したグローバルなポリシーをユーザー集団に対して適用するため、コールドスタートの課題に直面します。この課題の解決策として、この論文では Meta RLを用いてユーザー毎にポリシーを学習する方法を提案し、次のような構成であることを示しています。
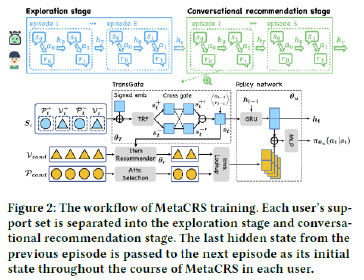
まず最初に、ユーザー集団からCRSのメタポリシーを学習し、ユーザーとの会話と推薦を数回試すことで新規ユーザーにメタポリシーを適応させます。次に有益なフィードバックを得るために設計したメタ探索ポリシーを用い、ユーザーと探索的な会話を行うことで、ユーザーの好みを特定します。最後に、推薦品質を最大化するためにポリシーに加え各ユーザーの推薦モジュールを適応させます。
これらの適応戦略のために、著者らはTransformerの状態エンコーダをバックボーンとして用い、会話と推薦コンポーネント間の学習信号を用い、ユーザーの好みをプロファイリングします。
ここまで紹介したように、レコメンドは機械学習やAIの技術を組み合わせた応用の一つで、これら技術の革新と拡張と相まって、まだまだ広がりを見せる実用と近い研究分野であることを実感しました。
Xu, Ziyun, et al: Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning
学習済み言語モデル(Pre-trained Language models (PLMs))は、さまざまな言語理解タスクにおいて、ラベル付き学習データに基づく微調整を必要としますが、顕著な成果を上げています。その微調整の一つであるプロンプトベース学習は、プロンプトをPLMのタスクガイダンスとして利用し、下流タスクをマスクされた言語問題に変えることで、効果的な微調整を実行します。
既存アプローチでは、プロンプトベース学習の高い性能は、プロンプトの手動作成とバーバライザーに大きく依存するため、実世界のシナリオでの適用を制限する可能性があります。
この問題を解決するために、この論文ではタスクに特化したプロンプトとバーバライザーを手動で設計することなくPLMを微調整するためのエンドツーエンドのフレームワークであるCP-Tuningを提案し、そのフレームワークの全体像を以下の図を用いて論文中で示しています。
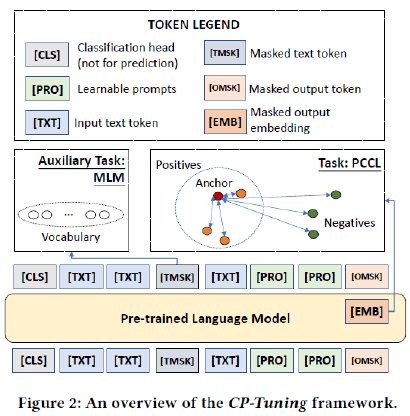
CP-Tuningは、タスクインバリアントな連続プロンプトエンコーディングとPair-wise Cost-sensitive Contrastive Loss(PCCL)を用いてPLMを学習します。
連続プロンプトエンコーディングは追加パラメタ学習を回避するため、埋め込み表現をPLMのエンコーダに直接与え、逆伝搬によりタスク適応を可能にします。
プロンプトのタスクインバリアンスを向上させるために、PCCLは異なるクラスを区別することを学習し、簡単なケースと難しいケースに異なるコストを課すことで判断境界をよりスムーズにしています。
レコメンドのように実用フェーズに近い研究でも、可能な限り技術を精査した上で、用途に応じて使い分けできる目利きが必要であると実感しました。
学習方法だけでなくモデルやフレームワークも常に更新されるだけではなく、その構成要素や技術まで見ると、既存技術やモデルに出会えます。例えば、Transformerもその要素の多くは以前のフレームワークやメカニズムです。
このような素晴らしい論文と同じカンファレンスで発表できるのも光栄ですが、今回はSession #8 (Recommendation and Learning)のセッションチェアを託されました。
その次のセッション、Session #9 (Language Models and Text Mining)「Friendly Conditional Text Generator」は自分の発表です。この場を借りて私の論文について紹介します。内容は「PLMs(今は(LLMs)の方が通りが良いかも)のドメイン適合のフレームワーク(アダプター)の提案」です。分かり難く言うと、PLMsが鳴女、フレームワークが愈史郎になるのでしょうか。論文中で次のフレームワーク、FCTGを提案しています。
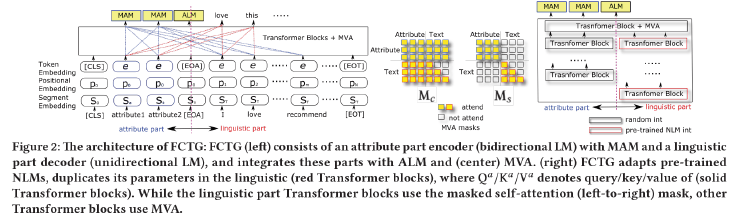
PLMsは条件(モデルへの指示、こちらもプロンプトの方が通りが良いかも)を与えると、条件に沿うトークンを再帰的にサンプリングすることでテキストを生成します。提案したフレームワークではモデルを適用するドメインに合わせてPLMsで学習済みのトークンの意味表現を更新するのではなく、PLMsとは別にドメイン特有のトークンの意味表現を学習させて、トークンのサンプリング前にPLMsとドメインの意味表現をマージしてサンプリングします。そのために参照範囲の異なるマスクを持つMulti View Attention (MVA)を論文中で提案しました。学習にはトークンレベルだけでなく、条件と文といったレベルでの意味的な類似性を目的関数に用います。FCTGはPLMsとは別の意味表現を持ってPLMsを更新することで、顕在化する「忘却」のリスク回避やモデル学習の計算コストの低減が期待できます。また、意味表現の学習をPLMsの更新と独立させるので、ドメイン固有の知識、例えばトークンでなく専門用語や記号といった通常とは異なる意味をモデルに理解させることができるだけでなく、秘匿性の高いデータを外部に出すことなくモデルをターゲットとなるドメイン向けに事後学習できることが期待できます。論文では、条件としてユーザーIDとアイテムIDのペアを与えると「その条件を満たした商品レビュー」、論文のタイトルを与えると「その論文のアブスト」を生成するという二種の異なるタスクで評価した結果を載せています。
現在はこのフレームワークをfew short learningのようなもうちょっと凝った?プロンプト学習、Chain of Thoughtや「複数のLLMs」に対応できるように拡張中です。
次はメキシコ
ビジネスランチでは次回の開催場所について紹介がありました。現地の方は冒頭で「開催場所のメリダは安全で治安の心配はありません!」と紹介を始めました。そのタイミングで「メリダ 治安」でネット検索を始めた人を何名か見かけました。治安は良さそうです。開催時期は今回同様に3月上旬、論文の投稿締め切りは8月半ばです。
今回はいつも以上に濃度の濃いカンファレンスで自分がどの国に居るのかを忘れてしまうぐらいでした。空港までの帰路で日本の有名建築物と似た建築物を見かけ、この類似性はどう定量化できるのか?AIでの判定はどうなるのか?と事実世界の「類似性」についても改めて考えました。偶然なのか、工法や建築基準及び建築事務所といった条件が揃った必然の結果なのでしょうか。

最後になりますが、ここまで読んでいただき有難うございます。
前回に引き続き今回も、ご尽力いただいた上司や同僚、この報告が世に出る機会を与えてくれた皆様にこの場を借りて御礼申し上げます。
川前 徳章 [かわまえのりあき]
エバンジェリスト
(データサイエンティスト)
2009年入社。大規模データの分散処理基盤の調査・導入から始まり、レコメンドシステム、情報検索、機械学習、自然言語理解と生成、AI等データサイエンスの研究開発とその導入に従事。現在は生成AIやマルチモーダルに向けたAIの研究開発を行っている。
各種データサイエンスに関する講演など対外的な活動も多く、KDD2021-、ICLR2022-、NeurIPS2021-、ICML2022-、AAAI2024-、WSDM2024-等のトップカンファレンスのPCや査読委員など、国内外でAIやデータサイエンス系の論文審査委員も多く担当している。2023年9月より上智大学大学院 非常勤講師も務める。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える