

ICML はInternational Conference on Machine Learningの略称で、今回で39回目の開催となります。今年は7月17日から23日に米国のボルチモアでオンサイト(現地)とオンラインを組み合わせたハイブリッド形式で開催されました。今回のICMLの論文査読を仰せつかった縁で、ICMLを自分の目で確かめ、そして参加者に直に話を聞いてみようとオンサイトで参加しました。実際、現地に足を踏み入れ参加した結果、参加者とのディスカッション等で、オンサイト参加のメリットを享受できました。
二年ぶりの国際会議
開催場所が米国なので移動は飛行機です。機内では、何度も観ている映画、「インセプション」を観ました。後から気が付いたのですが、今回の会議参加の感想は、まさにこの「インセプション」の追体験でした。昨年のICMLではCLIP等、AIの技術マップを塗り替える発表がありましたが、今年はどんな技術や発表に出会えるかという期待と、無事に帰国できるかという不安を抱えての出発でした。
米国への上陸だけでなく、国際会議への参加もAAAI以来、2年ぶりです。AAAI2020の出張レポートでは次のような所感を書いています。
私なりにこの分野のトレンドというか特徴が見えてきた気がします。AI実現の手段としてDeep Learningがトレンドであるのは勿論で、1)実用化に向けた課題解決、及び2)異分野との融合が多かったと感じました。
そのトレンドは今年のICMLでも継続していることを確認できました。
一方で、今回のICML2022は参加者のスタンスの違いを感じました。具体的には
- ハイブリッドによりセッション間の移動が簡単に
- ハイブリッドでも多くの参加者が(出席できれば)オンサイトを選択
開催形式が異なっても会議の様子と熱気は以前(AAAI)と変わりませんでした。
ICMLで扱うテーマ、主に発表される論文のテーマはAAAIと似ています。ICMLは手段としての機械学習、AAAIは機械学習を含めた手段のAIへの適用やそのアウトプットに主眼が置かれています。オンサイトの参加者数を比較するとAAAIの約4,000人に対し、ICMLは約2,700人でした。この参加者数だけを比較すれば少ないですが、各会議のSNS等でのフォロワー数や扱うテーマの幅を考えれば、AAAIと遜色なく盛況だったと思います。当時と比較して、国によってはまだ簡単に海外から参加できないため、オンラインのみの参加者はAAAIの時よりも多いかもしれません。日本からの参加者は会場では殆ど見かけませんでしたが、SNS等を見るとオンライン参加の方が多かったようです。

ICMLの開催会場はコンベンションセンタで、日本で類似する会場は幕張メッセでしょうか。会議の参加者は3,000人近くいましたが、会場が広いので十分にパーソナルスペースは確保できました。一方で、会議がハイブリッドであっても、私が参加したセッションの多くはセッションの会議室が満席で、現地開催を待ち望んでいた参加者が多いことを実感しました。またエキスポの会場や廊下でも参加者が集まってディスカッションや旧交を温めていて、ハイブリッドであることを忘れるぐらい盛況でした。
オンサイトでしかできない情報収集
会議にはスポンサーとして多くの企業が協賛していました。ITではお馴染みの企業から、新興企業、今までこの分野では見かけなかった世界的な製薬会社も協賛していることに機械学習の広がりを改めて実感した次第です。
これらの企業の多くは、セッションとは別のホールでブースを出展していました。その目的は、リクルート活動がメインであり、ブースにはリクルータが控えていました。企業によっては技術者も参加し、デモ展示やミニ講演をしていました。ブースに発表を終えたばかりの講演者がいることもあります。幸いなことに私は講演者にも会い、発表について詳しくディスカッションする機会を得ました。また、各企業の採用方針だけでなく、研究開発の進め方を含めた企業別の動向を横並びで伺うことができ、現地参加のメリットを実感しました。
ポスターセッションは口頭発表者も含めてポスターを展示しているので、直接ディスカッションできるメリットがあります。しかし、論文の数=ポスターの数が多いので、お目当てのポスターに辿り着くのにも一苦労です。少なくとも私はディスカッション時間より移動時間の方が長かったと思います。会場も広いですが、ポスターの数も参加者も多く、予定していたポスターの前に辿り着ける方が少ないかもしれません。というのも、あらかじめ、その日のポスターセッションで、お目当ての論文を決めておいても、そこに辿りつく途中で発表者と目が合えば、引き込まれて話を聞いてしまいますし、熱心にディスカッションしているポスターの前では足を止めて話を聞いてしまいます。所属は違っても、世界をリードする研究者同士の夢のディスカッションであれば尚更です。2時間の中で多くても話を聞いてディスカッションできる論文は10本あればいいでしょう。

今後が期待される興味深い論文
セッションはマルチセッションなので、自身の研究テーマに近いmultimodal, generationといったテーマに近いセッションを中心に参加しました。私の勉強不足でどこまでお伝えできるか不安がありますが、聴講した中で興味深い論文を幾つか紹介させていただきます。
Nichol, Alex, et al: GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
生成モデル、とりわけ画像生成のモデルに興味のある方には今最も関心ある論文の一つだと思います。最近では珍しくありませんが、既に公開されていて発表時点で有名になっているモデルの一つでしょう。画像生成のモデルではGANとその派生系が生成する画像のクオリティーの高さで他のモデルより人気がありますが、生成する画像の多様性に課題があります。
Nichol, Alex, et alはこの課題を解決するために論文でCLIPとDiffusion Modelを組み合わせたアプローチを提案しています。
Diffusion Modelも最近人気のある生成モデルで、この論文だけでなく、画像生成のモデル、例えばDALL-E2などでも利用されているので、モデルの名前は聞いたことがなくても、Diffusionという単語を最近よく目にすると思っている方も多いと思います。この会議でもDiffusion Modelを扱った論文が他にもあり、画像生成だけでなく他の生成モデルへの展開が期待されているモデルの一つとして注目されています。
Korbak, Tomasz, et al: Controlling Conditional Language Models without Catastrophic Forgetting
大量のデータから事前学習した生成モデル、例えばGPT-2,NeoやT5といったモデルが登場し、これらモデルのターゲットとなるドメインへの適合が機械学習でもテーマとなっています。この適合の際に生じる課題として、モデルの持つ能力を棄損してしまうCatastrophic Forgettingという問題が知られています。この問題の解決策として、制御対象をエネルギーベースのモデルとdistributional policy gradients ( DPG)で表現するアプローチが提案されていますが、そのままでは条件付きの分布に適用できないという限界も知られています。
Korbak, Tomasz, et alはDPGを拡張し、条件付エネルギーモデルを近似可能なConditional DPG(CDPG)をこの論文で提案しています。この論文ではCDPGを機械翻訳、要約、コード生成のタスクGPT-NEOとT5の両モデルを事前学習モデルとして実験を行い、CDPGの有効性を示しています。例えば、従来のreinforcement learningを用いたアプローチに比較して翻訳のタスクの実験でCDPGは多様性や品質を低下させなかったことでCatastrophic Forgettingの緩和を示しています。
Javaloyet, Adri´an, et al: Mitigating Modality Collapse in Multimodal VAEs via Impartial Optimization
この論文はVariational Autoencoder (VAE)ベースのマルチモーダルデータの学習フレームワークを提案しています。従来のVAEベースのモデルは、マルチモーダルデータ、例えば、画像-テキストペアのデータを与えた際に、画像だけをフィッティングし、キャプションを無視するなど、一部のモダリティに注力することが知られています。Javaloyet, Adri´an, et alはこの欠点をmodality collapseと呼び、その原因がgradient conflictsにあることに着目し、解決策として既存のmultitask learning(MTL)を利用した学習のpipelineから構成されるフレームワークを提案しています。
一般にマルチモーダルのアプリケーションは欠落データの補完や異種のデータを同時に生成するため、これら異種データの確率分布をVAEは正確に近似することが求められます。その尤度計算はデータ間の不公平性を回避するため、学習過程におけるgradientsをモダリティ間で公平に更新する必要があります。その際、モーダル毎のgradients間の相違が大きい場合、全体の勾配計算において一部のモーダルのgradientに関連した共通パラメータの更新を優先することになります。その結果生じる問題がmodality collapseとなります。この解決策として、論文ではMTLで研究されているgradients間の公平な最適化を活用し学習中の公平性ブロックのバックワードパスを修正する学習方法を提案しています。この学習の様子は論文中の図で次のように示されています。
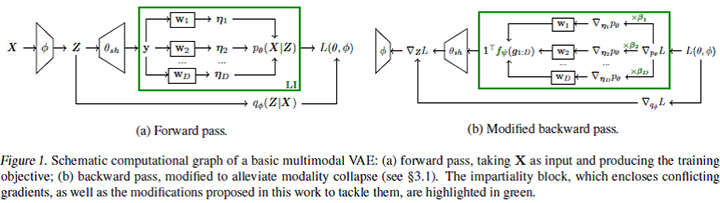
個人的にはアプローチだけでなく本文も洗練され、内容も分かりやすく、論理構成も大変参考になる論文と思いました。
Poklukar, Petra, et al: Geometric Multimodal Contrastive Representation Learning
こちらもマルチモーダルの学習の論文です。背景として、この分野で扱うデータには、異なるチャネルから取得されるために不均質という特性があります。そのため、モデルのテスト時に欠測に対しロバストかつ情報量を含む表現を学習することは現在進行中の課題です。マルチモーダルデータの表現は、異種の形式を持つデータを同一空間へ投影し、その後、その空間で学習することで獲得されます。その際にheterogeneity gapという課題があり、この解決手段としてVAEベースの frameworkを拡張した方法が提案されています。VAEとその派生モデルは生成ベースの手法ではよく利用されている一方、データの再構成というモデルの目的により完全かつモダリティに特化した表現を学習することが難しい側面があります。
Poklukar, Petra, et alがこの論文で提案するGMCは空間への投影を、最初にモダリティ特異的基底ネットワークで固定長の中間表現に符号化し、次に共通ヘッドを用いて共通の表現空間へ投影する二段階のアプローチを提案しています。この学習フレームは論文中で次の図で示されています。
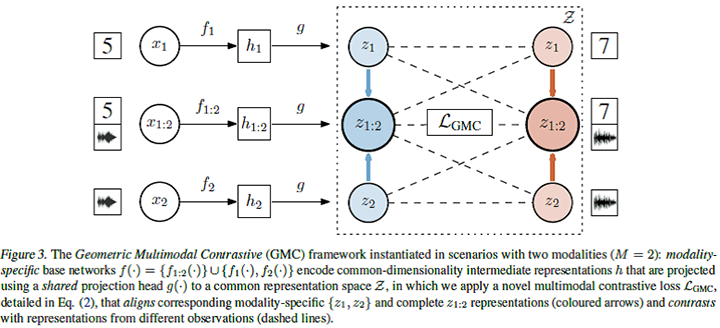
この表現空間に、multimodal contrastive lossを適用することで、モーダルを超えたデータ毎の共通表現が学習されます。実験では、GMCが様々な学習問題において、モダリティ情報が欠落している場合でも、計算効率が良く(類似のモデルよりも90%少ないパラメータで済むことが多い)、既存の最先端アプローチとの統合が容易という特徴と合わせて、最先端の性能を達成できるとPoklukar, Petra, et alは主張しています。
彼らの論文はマルチモーダルの表現学習に前出のJavaloyet, Adri´an, et alとは異なるアプローチを提案し、中間表現というワンクッションの導入とcontrastive learningの可能性を示しました。
Baevski, Alexei, et al: data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
こちらもマルチモーダル分野の論文で、モダリティ非依存の自己教師あり学習を提案しています。これまでの自己教師あり学習はモダリティ、例えば画像や音声などのデータ種別に依存した学習を必要としていました。Baevski, Alexei, et alが提案するフレームワークはmasked predictionとlatent target representationsを組み合わせ、単語、視覚的トークン、発話単位など、局所的なモダリティに特化した対象ではなく、入力全体からの情報を含む文脈的な潜在表現を予測するように学習しています。この学習ではTransformerネットワークをteacherとstudentの二つのモードを用いて訓練しています。
モダリティ非依存の学習という点でも興味深いですが、前出のPoklukar, Petra, et alが中間表現であるのに対し、Baevski, Alexei, et alは文脈的な潜在表現を予測対象として学習するのが面白いと思いました。今回発表された多くの論文の中で、個人的にはこのタイトルがシンプルかつ多くの情報量を持っていたので、タイトルの重要さを再認識させてくれた論文でした。正確には会議前から公開され、読んでいたのですが、会議では企業ブースで休憩?していた著者と直接話すことで理解も深まり、私にとり今会議で最も印象に残る論文でした。
Hawthorne, Curtis, et al: General-purpose, long-context autoregressive modeling with Perceiver AR
最後に紹介する論文はマルチモーダルは勿論、Transformerに関わるモデルやフレームワークを御存知であれば興味を引く論文の一つでしょう。Transformersにおける主要要素の一つであるself attentionは、入力シーケンスがN個に分割された場合、計算もメモリもNの二乗のオーダに従います。これはマルチモーダルに限らず、入力シーケンスが長い他のデータを扱う際のTransformersの課題となります。この課題解決を試みた代表的なモデルの一つであるTransformer-XLはcached attentionを提案しています。Hawthorne et alは入力データに対しcross-attentionのマスクを持つcross-attendの上にself-attentionのマスクを持つLatent self-attendを積み上げる方法をこの論文で提案しています。その構成は論文中の次の図(左側)で示されています。
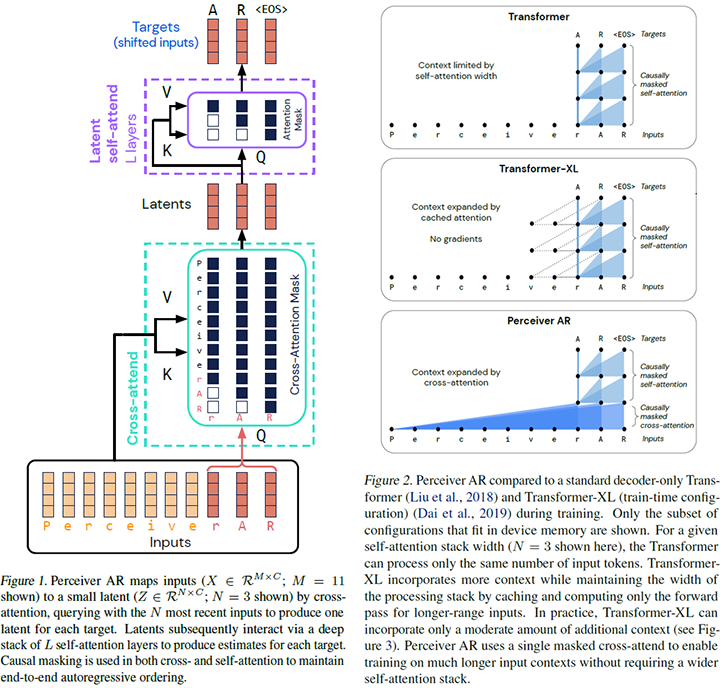
Transformerは入力シーケンスをトークンに分割して処理します。左側の図が示すように、入力シーケンスをN個にトークナイズした場合、後ろからn個のトークンをcross-attendのqueryとすれば、それ以前のN-n個のトークンはcross-attendのkey/valueとなります。その結果、通常のself-attendではトークン数がN個のままであるのに対し、cross-attendの出力ではトークン数がN個からn個と小さくなります。この出力を論文ではLatentsと呼び、既存モデル同様にself attentionのquery/key/valueとして扱います。その結果、モデルの計算複雑性は入力のトークン数のN個でなくnに比例することになります。右側の図が既存のモデルとのattendするトークン数の違いを示しています。Transformerの処理可能なトークン数が大きくなれば、処理できる入力シーケンス長も長くなります。Hawthorne, Curtis, et alはバッチサイズ1としてTPUv3を用いた実験では、トークン数の上限がTransformerで2048、Transformer-XLは8192, Perceiver ARでは65536という結果を示しています。勿論、この結果はブロック数により変化するようです。
Hawthorne, Curtis, et alの論文は、私が今回の会議で見た最多著者数?の論文でした。インセプションの見どころの一つに「無重力シーンでの格闘」があります。この撮影トリックはシンプル(でも大掛かり)で古典的ですが、その視覚的効果は色あせていません。この論文から「無重力シーン」並みのインパクトを私は受けました。音楽の世界ならばジャミロ・クワイのVirtual Insanityのビデオになるでしょうか。Transformersの構成要素はそれほど多くないのですが、それら既知の要素を組み合わせ、この論文は異なるattentionの積み重ねるというシンプルなアプローチで、圧倒的なパフォーマンスを達成したことに深い感動を覚えました。一方で、入力シーケンスほど多くはありませんが、論文の著者が15人もいらっしゃるので、著者間のattentionはどうなっているのかが気になりました。
ICMLでは事前に録画された講演が多数ありましたが、ラボ、自宅等々で録画されており、時々、背景が「ここは映画のセットなのだろうか?」「後ろの抽象画は有名な作家のもの?自分で描いたもの?」と気になることもありました。
会議前から公開されている論文もかなりあるので、可能であれば、興味のある論文は事前に読み込んで参加すると、質問やディスカッションも深めることができます。
これまでは気になるセッションがあっても物理的移動があり、聴講したい論文の発表に間に合わないことも多々ありましたが、ハイブリッドになったことで物理的移動も無くなり、タイムスケジュールとの乖離や情報ロスを小さくすることができるようになりました。具体的には、(乗ったことはないですが)飛行機のファーストクラスだけでなく、(もう乗れないですが)500系の個室グリーン車からも会議に参加できる時代になったわけです。しかし、発表者の立場からするとどうなのでしょうか?私も別の会議にオンラインで参加し、そこで発表したこともありますが、たとえリアルタイムであってもオンラインでは参加者の反応が分かりにくいので、私はできればオンサイトの方がよいと思いました。
夢から現実へ
繰り返しになりますが、講演を聞くだけならばオンラインでも可能です。論文の背景や実装及び開発のプロセスだけでなく、各研究者の進行中の研究まで話を聞くことができれば、オンサイト参加のメリットが出てきます。私自身、今回のICMLに参加したことで、普段は接する機会の少ないテーマの最新動向を知ることができました。また、マルチセッションといえども私の調査対象ではなく、たくさんの空き時間ができてしまったらどうしよう?という心配も杞憂に終わりました。
インセプションの設定では現実世界の1分は、一階層の夢の世界の20分に相当しています。ICMLのようなトップカンファレンスに参加することで、通常よりも多くの英知や知見に触れるので、同じ時間でも普段の倍以上の刺激的な経験と情報が得られるので自己成長のスピードが速く(なったように感じる)、文字通り夢の世界と言えるでしょう。そういった夢の場所から現実に引き戻す役割をしているのがトーテム。私のトーテムはものではなく時差ぼけでした。最終日になっても日中に襲ってくる睡魔との闘いで現実の世界に引き戻されました。
当時の状況で海外出張は私以上に周囲の方が苦労されたことと思います。私を送り出してくれた上司や同僚の皆様はまさに現実世界のドリームチームです。この場を借りて現地でお世話になった全ての皆様とドリームチームへ感謝申し上げます。
川前 徳章 [かわまえのりあき]
エバンジェリスト
(データサイエンティスト)
2009年入社。大規模データの分散処理基盤の調査・導入から始まり、レコメンドシステム、情報検索、機械学習、自然言語理解と生成、AI等データサイエンスの研究開発とその導入に従事。現在は生成AIやマルチモーダルに向けたAIの研究開発を行っている。
各種データサイエンスに関する講演など対外的な活動も多く、KDD2021-、ICLR2022-、NeurIPS2021-、ICML2022-、AAAI2024-、WSDM2024-等のトップカンファレンスのPCや査読委員など、国内外でAIやデータサイエンス系の論文審査委員も多く担当している。2023年9月より上智大学大学院 非常勤講師も務める。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える