
NTTドコモソリューションズ株式会社 エバンジェリスト(データサイエンティスト) 川前 徳章
人とコミュニケーションするChatbot(チャットボット、以下Chat)について、「データマネジメント2021~データによる可視化が現実と仮想を繋ぐ~」(日本データマネジメント・コンソーシアム(JDMC)主催)での川前エバンジェリストの講演をもとに、NTTコムウェアが取り組む、自然言語処理/理解を行うAI活用の最新動向を紹介する本レポート。後編では画像をメタデータ不要で検索するMulti-modal search(マルチモーダル検索)などについて紹介する。
画像など非テキストデータをメタデータ不要で検索するMulti-modal search
テキスト、画像、動画、音声といった異種データをシームレスに扱うMulti-modalという技術がある。
一般的に、非テキストデータである画像等のメディアデータの検索では、撮影日や撮影場所等の付随する情報あるいはそれに紐づくテキスト、いわゆるメタデータを検索している。そのため、通常の画像検索ではメタデータに基づき画像を検索するが、Multi-modalでは画像の内容を理解した検索が可能となる。
NTTコムウェアでも、Multi-modal search、Multi-modal Conversational searchに取り組んでいる。
前編で紹介したDeepLearningの第4の学習モデルといわれるTransformerにおいてBERT(Googleが発表した学習モデル)を中心に整理した図に、この2つの取り組みの位置付けを示す。
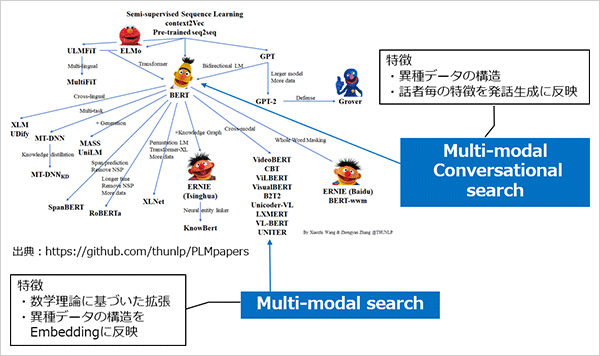
Multi-modal Conversational searchについては、後段の「質問者を納得させる会話」の項で詳しく説明するが、まず、Multi-modal searchとは何か、日常での一般的な検索といえるUni-modal searchと比較してみる。
Uni-modal searchは、ユーザーが入力した検索クエリに対して、検索結果はテキスト、画像などのいずれか一種類のデータで答えが返される(最近はそのハイブリッドもあるが)。
これに対して、Multi-modal searchは、
1)検索結果に複数のデータ形式が異なる結果を含む
あるいは、
2)検索条件と異なったデータ形式の結果を返す
ことができる。
つまり、「単語と画像の組み合わせ」を検索クエリにでき、検索することができる。
言いかえると、Uni-modal searchは、検索対象となる画像のメタデータに対する全文検索であるため、メタデータのある画像しか検索できないという制限がある。Multi-modal searchは画像の特徴量とメタデータから画像の内容(何の画像であるのか)を理解するため、メタデータのない画像も検索できる。つまり、Multi-modal searchは検索対象となる異種データの内容まで理解して検索しているといえる。
密度と距離で意味を捉えるMulti-modalの双曲空間とは?
Multi-modalの実現には、テキストを構成する単語と画像等の非テキストの両方を同一空間に埋め込む必要がある。一般にこの空間としてユークリッド空間が用いられることが多いが、私たちは双曲空間を用いる。この空間は私たちになじみのある二次元や三次元で表現されるユークリッド空間とは異なり、曲がった空間(多様体)であり、ユークリッド空間に比べて圧倒的に広い空間になる。双曲空間のイメージとしてエッシャーの絵が参考になる。

この絵で表現されているように、円の周辺に行くほど「密」な空間になっているのが大切な点で、一般的なユークリッド空間ではこうした表現はできない。
単語には、意味的に抽象的なものがあれば、具体的なものもある。写真や画像も、多くの人が写っているものがあれば、1人で写っているものもある。また、ビルが立ち並んでいるものがあれば、1軒の家のみが写っているものもある。これらをいくつかの階層構造で考えると、階層構造の枝分かれは指数関数的に増えていくことになる。そのため、ユークリッド空間で単語と画像のような異種データの関係性の距離を計算すると、大きな情報のロスが発生してしまう。
そこで、従来はユークリッド空間に埋め込んでいた単語間の関係を、双曲空間に埋め込めば、周辺が密になる双曲空間の特徴を活かして、単語や画像の異種データの階層構造やその距離をうまく反映できると着想し、NTTコムウェア独自の提案モデルの開発を進めている。
このNTTコムウェア提案モデルもTransformerをベースとしており、画像とテキストの依存関係を同時に学習する。
画像同士、テキスト同士のEmbedding(埋め込み 前編参照)はユークリッド空間でAttention(注意)の距離を計算しているが、画像とテキスト、テキストを構成する単語の間はぞれぞれのEmbeddingをユークリッド空間から双曲空間に射影し、双曲空間で距離を計算する。
対象となったMulti-modal searchの代表的なタスクはT2I(テキストを与えて正しい画像を検索する)、I2T(画像を与えて正しいテキストを検索する)を用いており、両タスクにおいて、良好な結果を得ている。

上半分の表ではテキストのクエリに対して、NTTコムウェア提案モデルは正解を含み、また、ほぼ似た内容の画像を候補として提示している。
また、概念感の距離、意味的な近さを計算可能とした結果が下半分の表である。クエリから「-dog(犬を除く)」および「-grass(草を除く)」とした結果、それぞれその通りの意味の画像を(メタデータを用いず)提示できている。
「質問者を納得させる会話」を支えるMulti-modal Conversational search
Chatの対話自動生成に使うMulti-modal Conversational searchは、自然文入力に加え、画像などの非テキストデータを併用して、「人が専門家と対話しているような」検索サービスをECサイト等で実現する技術である。
例えば、観たい映画を検索する際、レコメンドシステムは、レコメンドシステムの判断や感じ方を表す会話を活用して、専門家ならではの発話や推薦理由を表示してレコメンドを提供することで、質問者を納得させる。
「Chatの対話自動生成には業務知識を持つ必要があるため、業界領域に特化したデータとWebなどで公開されているデータを合わせて実際に学習させます。するとあたかも専門知識を持つ担当者と会話した時のような説明的な要素を含んだ発話の生成ができ、質問者が納得できる対象の表示やレコメンドを提供できる、これが大きな強みです」(川前)
NTTコムウェアが提案するMulti-modal Conversational searchのモデルでは、発話のみのUni-modalと、画像を用いた発話が可能になるMulti-modalの両方を内包している。
さらに、Speaker/Attribute Embeddingによって話者(質問をする人)それぞれの特徴を発話に反映できるようになっている。
これにより、話者の属性により答えやレコメンドする内容を変える。つまり、従来の発話自動生成ではできなかった「カスタマイズされた発話」を可能としている。
NTTコムウェアはMulti-modal search、Multi-modal Conversational searchの研究開発を進め、世界の先進企業の技術に負けない、実際の業務で使える、検索や自動発話生成の機能を備えたChatを誕生させようとしている。

※Googleは、Google LLC の商標または登録商標です。




エバンジェリスト(データサイエンティスト)
- 川前 徳章
- NTTドコモソリューションズ株式会社
エンタープライズソリューション事業本部
コラム一覧
- 生成AIの里 第五回:Promptがうまく使えなくて
- 生成AIの里 番外地:NTTコムウェアのエバンジェリストの目に映る最新AI動向と技術開発
- 生成AIの里 第四回:Promptがうまく言えなくて。。。:Pronto?Llama3、アンモナイトについて教えて!
- 生成AIの里 第三回:生成モデルと検索モデル(後編):昔のことが忘れられない―誤差逆伝播法はニューラルネットワークの呼吸である―
- 生成AIの里 第二回:生成モデルと検索モデル(前編):Prêt-à-porter ou haute couture?
- ACL2023に参加しました:カール起きて!ナイアガラ上空にジャコビニ流星が!
- 生成AIの里 第一回:How many LLMs must we learn?
- WSDM2023に参加/発表しました ―デジャブか類似か―
- KDD2022にも参加しました ―リソースと人生は有限、では無限なのは?―
- ICML2022に参加してきました ―深層学習は何階層?―
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <後編>AIが解く、「公園で遊ぶ犬の画像」―「芝」=?
- 自然言語処理/理解を中心としたAIの動向、実用化進む「Chatbot」はここまで来た! <前編>AIが測る言葉の距離?
- コムウェアは電気羊の夢を見るか?
- AAAI 2020に参加してきました ―データサイエンティストの熱狂―
- 哲学するAI~「愛」から「お金」を引いたら何が残るか~
- AIは人間の仕事を奪うのか?データサイエンスの視点から考える